 王张开
王张开about
名词解释
MySQL所使用的SQL语言是用于访问数据库的最常用标准化语言,SQL语言可以分为:
DDL(Data Definition Language)语言:数据定义语言,用来定义数据库对象,如数据库、数据表和数据字段;
DML(Data Manipulation Language)语言:数据操作语言,用来对数据库表中的数据进行增删改查操作;
DQL(Data Query Language)语言:数据查询语言,用来查询数据库中表的记录;
DCL(Data Control Language)语言:数据控制语言,用来创建数据库用户、控制数据库的访问权限。
安装
# 下面这两个二选一进行安装,推荐的话,如果mysqlclient安装不报错,就用mysqlclient,报错的话,不用处理报错,我们直接改用安装pymysql就完了
pip install mysqlclient
pip install pymysql
# 然后安装sqlalchemy最新版
# pip install -U sqlalchemy
# 我的环境是win11,sqlalchemy用的是2.0.20版本的,且安装mysqlclient没报错
pip install sqlalchemy==2.0.20
pip install mysqlclient=2.2.0
>>> import sqlalchemy
>>> sqlalchemy.__version__
'2.0.20'注意,我这里用的sqlalchemy是2.x版本,与1.x版本有些地方稍有不同,这点需要注意。
而且异步那块,不同的系统实现也不相同,这都是要注意的。
连接数据库
各种数据库连接配置,官档:https://docs.sqlalchemy.org/en/20/core/engines.html#database-urls
我的环境是win11 + Python3.10 + sqlalchemy2.0.20 + mysqlclient2.2.0 + MySQL8.0.31
# -*- coding = utf-8 -*-
from sqlalchemy import URL
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
# engine = create_engine(
# # mysqlclient + sqlalchemy 你这么写URL
# url="mysql://root:123@127.0.0.1:3306/alchemy?charset=utf8mb4", # 注意,数据库需要我们自己提前在数据库中手动创建好
# # pymysql + sqlalchemy 你这么写URL
# # url="mysql+pymysql://root:123@127.0.0.1:3306/alchemy?charset=utf8mb4",
#
# echo=True, # 当设置为True时会将orm语句转化为sql语句打印,一般debug的时候可用
# pool_size=10, # 连接池的数据库连接数量,默认为5个,设置为0时表示连接无限制
# max_overflow=30, # 连接池的数据库连接最大数量,默认为10个
# pool_recycle=60 * 30 # 设置时间以限制数据库连接多久没使用则自动断开(指代max_overflow-pool_size),单位:秒
# )
# 关于URL的处理,你也可以这样
url = URL.create(drivername="mysql", username='root', password='123', host='127.0.0.1', port=3306, database='alchemy')
engine = create_engine(
# mysqlclient + sqlalchemy 你这么写URL
url=url,
# pymysql + sqlalchemy 你这么写URL
# url="mysql+pymysql://root:123@127.0.0.1:3306/alchemy?charset=utf8mb4",
# echo=True, # 当设置为True时会将orm语句转化为sql语句打印,一般debug的时候可用
pool_size=10, # 连接池的数据库连接数量,默认为5个,设置为0时表示连接无限制
max_overflow=30, # 连接池的数据库连接最大数量,默认为10个
pool_recycle=60 * 30 # 设置时间以限制数据库连接多久没使用则自动断开(指代max_overflow-pool_size),单位:秒
)
# 基于底层数据库驱动建立数据库连接会话,相当于cursor游标
Session = sessionmaker(bind=engine)
# 后续通过session进行增删改查等操作
session = Session()创建模型类对象
init_app.py代码不变:
# -*- coding = utf-8 -*-
from sqlalchemy import URL
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
url = URL.create(drivername="mysql", username='root', password='123', host='127.0.0.1', port=3306, database='alchemy')
engine = create_engine(url=url, echo=True, pool_size=10, max_overflow=30, pool_recycle=60 * 30)
Session = sessionmaker(bind=engine)
session = Session()模型类我都统一在models.py中实现:
# -*- coding = utf-8 -*-
from datetime import datetime
# sqlalchemy包导入好了常见的字段类型,我们这里直接导入即可,我为了少敲几个字,通过as语句起个简单的别名
import sqlalchemy as db
"""
2.0之前的版本,这么导入
from sqlalchemy.ext.declarative import declarative_base
到了2.0版本,这么导入就有这个MovedIn20Warning
MovedIn20Warning: The ``declarative_base()`` function is now available as sqlalchemy.orm.declarative_base(). (deprecated since: 2.0) (Background on SQLAlchemy 2.0 at: https://sqlalche.me/e/b8d9) Model = declarative_base()
如何解决就是,按照提示,改为这么导入
from sqlalchemy.orm import declarative_base
"""
# from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import declarative_base
from init_app import engine
# 模型类对象的基类,内部提供了数据库的基本操作以及共同方法
Model = declarative_base()
class Books(Model): # 模型类类名可以按需指定,但必须指定Model基类,才会在后续的操作中通过sqlalchemy进行数据库迁移
""" 书籍表 """
__tablename__ = "tb_books" # 必须这么指定该模型类在数据库中对应的表名
id = db.Column(db.Integer, primary_key=True, autoincrement=True, comment='主键ID')
title = db.Column(db.String(32), nullable=True, comment='书籍名称') # db.String --> varchar
price = db.Column(db.DECIMAL(precision=10, scale=2), comment='书籍价格')
pub_date = db.Column(db.Date, default=datetime.now, comment='书籍出版日期')
publish = db.Column(db.String(32), nullable=True, comment='书籍出版社')
def __repr__(self):
"""
当实例对象被使用print打印时,自动执行该__repr__方法,
__repr__方法和__str__方法效果一样,
返回值必须时字符串格式,否则报错!!!
"""
return f"<{self.title}>"
class Users(Model): # 模型类类名可以按需指定,但必须指定Model基类,才会在后续的操作中通过sqlalchemy进行数据库迁移
""" 用户表 """
__tablename__ = "tb_users" # 必须这么指定该模型类在数据库中对应的表名
id = db.Column(db.Integer, primary_key=True, autoincrement=True, comment='主键ID')
name = db.Column(db.String(20), comment='用户名')
sex = db.Column(db.Boolean, default=True, comment='用户性别')
age = db.Column(db.SmallInteger, comment='用户年龄')
mobile = db.Column(db.BigInteger, comment='手机号')
email = db.Column(db.String(64), comment='邮箱')
pwd = db.Column(db.String(20), comment='密码')
classes = db.Column(name="class", type_=db.SMALLINT, comment='用户班级')
addr = db.Column(db.Text, comment='家庭住址')
status = db.Column(db.Boolean, default=1, comment='状态')
add_date = db.Column(db.Date, default=datetime.now, comment='添加日期')
birth_datetime = db.Column(db.DateTime, default=datetime.now, comment='出生时间')
def __repr__(self):
return f"<{self.name}>"
if __name__ == '__main__':
# 将当前文件中所有继承Model基类的模型类,都进行数据库迁移,在数据库中真正的建立相应的表
# 该creat_all方法重复执行,已创建的表不会重新创建,哪怕你修改了模型类,
Model.metadata.create_all(engine) # engine是init_app中创建好的engine对象
# 删除所有继承Model基类的模型类
# Model.metadata.drop_all(engine) # engine是init_app中创建好的engine对象直接运行这个models.py文件,就会在数据库中真正的把表创建出来。
字段类型和约束参数
name属性,指定该字段在数据库中的名字,比如class字段,这个class是Python的关键字,我们在模型类中无法指定class作为字段名,所以模型类定义该字段时,可能改为classes或者class_等其他别名,但数据库中class可以作为字段名的,所以可以通过name属性指定。
sqlalchemy中关于float类型的坑
# -*- coding = utf-8 -*-
from sqlalchemy import URL
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
import sqlalchemy as db
from sqlalchemy.orm import declarative_base
from sqlalchemy.dialects import mysql
url = URL.create(drivername="mysql", username='root', password='123', host='127.0.0.1', port=3306, database='alchemy')
engine = create_engine(url=url)
Session = sessionmaker(bind=engine)
session = Session()
Model = declarative_base()
class Test(Model):
__tablename__ = "tb_test"
id = db.Column(db.Integer, primary_key=True, autoincrement=True, comment='主键ID')
f1 = db.Column(db.Float) # 'f1': 10.7983 对应Python中的float类型,对应MySQL中的float类型
f2 = db.Column(db.Float()) # 'f2': 10.7983 对应Python中的float类型,对应MySQL中的float类型
f3 = db.Column(db.Float(10, 2)) # 'f3': Decimal('10.7983000000') 对应Python中的Decimal类型,对应MySQL中的float类型
f4 = db.Column(db.Float(precision=10, asdecimal=False, decimal_return_scale=2)) # 'f4': 10.7983 对应Python中的float类型,对应MySQL中的float类型
f5 = db.Column(db.FLOAT(precision=10, asdecimal=True, decimal_return_scale=2)) # 'f5': Decimal('10.80') 对应Python中的Decimal类型,对应MySQL中的float类型
f6 = db.Column(db.DECIMAL(precision=10, scale=2)) # 'f6': Decimal('10.80') 对应Python中的Decimal类型,对应MySQL中的Decimal类型
f7 = db.Column(mysql.FLOAT(precision=10, scale=2)) # 'f7': 10.8 对应Python中的float类型,对应MySQL中的float类型
f8 = db.Column(mysql.DECIMAL(precision=10, scale=2)) # 'f8': Decimal('10.80') 对应Python中的Decimal类型,对应MySQL中的Decimal类型
f9 = db.Column(mysql.DOUBLE(precision=10, scale=2)) # 'f9': Decimal('10.80') 对应Python中的Decimal类型,对应MySQL中的double类型
f10 = db.Column(db.Numeric(precision=10, scale=2)) # 'f10': Decimal('10.80') 对应Python中的Decimal类型,对应MySQL中的Decimal类型
if __name__ == '__main__':
Model.metadata.drop_all(engine)
Model.metadata.create_all(engine)
# 插入数据
f = "10.7983174936553573"
test_obj = Test(f1=f, f2=f, f3=f, f4=f, f5=f, f6=f, f7=f, f8=f, f9=f, f10=f)
session.add(test_obj)
session.commit()
# 查询
print(session.get(Test, 1).__dict__) # {'_sa_instance_state': <sqlalchemy.orm.state.InstanceState object at 0x000001A63BF64A00>, 'f3': Decimal('10.7983000000'), 'f5': Decimal('10.80'), 'f9': Decimal('10.80'), 'id': 1, 'f7': 10.8, 'f8': Decimal('10.80'), 'f1': 10.7983, 'f2': 10.7983, 'f6': Decimal('10.80'), 'f10': Decimal('10.80'), 'f4': 10.7983}
print('f1', session.query(Test).filter(Test.f1 == 10.7983).all()) # f1 []
print('f1', session.query(Test).filter(Test.f1 == 10.80).all()) # f1 []
print('f2', session.query(Test).filter(Test.f2 == 10.7983).all()) # f2 []
print('f2', session.query(Test).filter(Test.f2 == 10.80).all()) # f2 []
print('f3', session.query(Test).filter(Test.f3 == 10.7983).all()) # f3 []
print('f3', session.query(Test).filter(Test.f3 == 10.80).all()) # f3 []
print('f4', session.query(Test).filter(Test.f4 == 10.7983).all()) # f4 []
print('f4', session.query(Test).filter(Test.f4 == 10.80).all()) # f4 []
print('f5', session.query(Test).filter(Test.f5 == 10.7983).all()) # f5 []
print('f5', session.query(Test).filter(Test.f5 == 10.80).all()) # f5 []
print('f6', session.query(Test).filter(Test.f6 == 10.7983).first()) # f6 None
print('f6', session.query(Test).filter(Test.f6 == 10.80).first()) # f6 <__main__.Test object at 0x000001A63BF22650>
print('f7', session.query(Test).filter(Test.f7 == 11).first()) # f7 None
print('f8', session.query(Test).filter(Test.f8 == 10.80).first()) # f8 <__main__.Test object at 0x000001A63BF22650>
print('f8', session.query(Test).filter(Test.f8 == 10.80).first().__dict__) # f8 {'_sa_instance_state': <sqlalchemy.orm.state.InstanceState object at 0x000001A63BF64A00>, 'f3': Decimal('10.7983000000'), 'f5': Decimal('10.80'), 'f9': Decimal('10.80'), 'id': 1, 'f7': 10.8, 'f8': Decimal('10.80'), 'f1': 10.7983, 'f2': 10.7983, 'f6': Decimal('10.80'), 'f10': Decimal('10.80'), 'f4': 10.7983}
print('f9', session.query(Test).filter(Test.f9 == 10.80).first().__dict__) # f9 {'_sa_instance_state': <sqlalchemy.orm.state.InstanceState object at 0x000001A63BF64A00>, 'f3': Decimal('10.7983000000'), 'f5': Decimal('10.80'), 'f9': Decimal('10.80'), 'id': 1, 'f7': 10.8, 'f8': Decimal('10.80'), 'f1': 10.7983, 'f2': 10.7983, 'f6': Decimal('10.80'), 'f10': Decimal('10.80'), 'f4': 10.7983}
print('f10', session.query(Test).filter(Test.f10 == 10.80).first().__dict__) # f10 {'_sa_instance_state': <sqlalchemy.orm.state.InstanceState object at 0x000001A63BF64A00>, 'f3': Decimal('10.7983000000'), 'f5': Decimal('10.80'), 'f9': Decimal('10.80'), 'id': 1, 'f7': 10.8, 'f8': Decimal('10.80'), 'f1': 10.7983, 'f2': 10.7983, 'f6': Decimal('10.80'), 'f10': Decimal('10.80'), 'f4': 10.7983}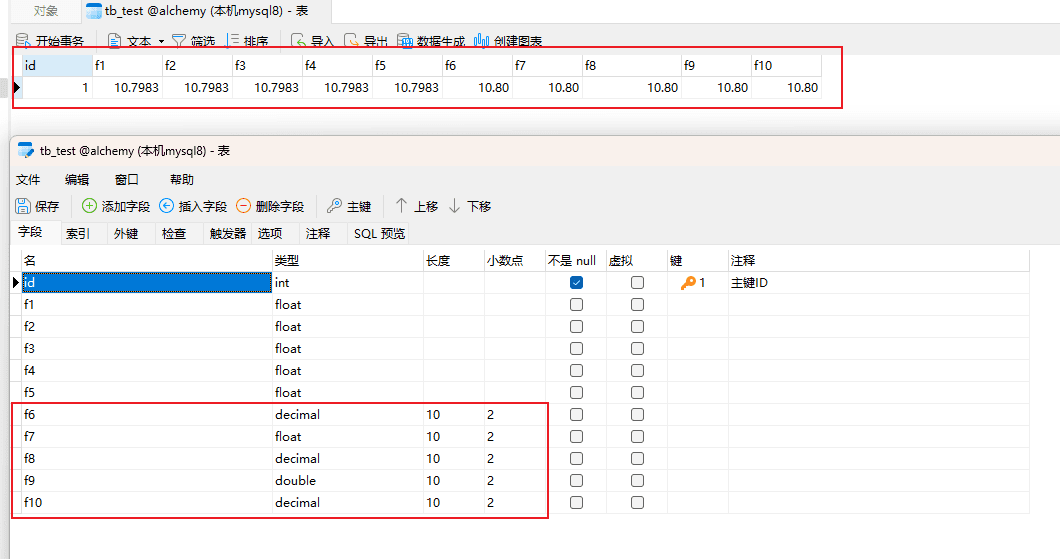
通过截图和代码运行示例可以总结:
sqlalchemy中的Float、FLOAT类型对应的是MySQL中的float类型,但是,注意观察截图f1~f5中的长度和小数点列都是空的,表示可以存储小数,但是没有小数点位,这就很坑了,这就意味着查询条件如果是浮点型的话,你查询不到结果,由上面的代码示例可证明。
为了解决sqlalchemy中的Float、FLOAT的弊端,我们采取的解决办法是:
- 如果使用Float、FLOAT的话,可以采用sqlalchemy的DECIMAL类型,然后指定整数位和小数位的个数。
- 如果你读sqlalchemy的源码的话,你会发现sqlalchemy的Float、FLOAT、DECIMAL这几个类型,都继承的是的sqlalchemy的Numeric类型,所以,你可以直接使用Numeric类型定义字段。
- 参照上例,如果你用的是MySQL数据库,那么你定义字段时,可以从
from sqlalchemy.dialects import mysql导入MySQL的FLOAT、DECIMAL、DOUBLE类型,但这个不建议使用,因为有可能数据库更改为别的数据库。当然了,如果是MySQL的话,这种方式是可以考虑的。 - 最终,我建议呢,使用sqlalchemy的DECIMAL和Numeric来处理浮点数。
另外,Python中,json是无法直接序列化DECIMAL的类型的,在处理DECIMAL类型时,你可以通过Python的float类型将DECIMAL类型转为float类型就可以序列化了。
当然了,如果你留心截图中的MySQL的存储结果,你会发现浮点型保留指定小数位时,发生了进位问题。
10.798进位成了10.80,如果你不想让其进位怎么办,其实在开发中,对于这种浮点型,我们通常把它转为字符串,然后以字符串的形式存储到数据库,这样不会丢失浮点型数据的精度了,在使用时,通过编程语言进行转为指定类型再处理。
单表的增删改查
有了模型类,也进行了数据库迁移,我们就来学学sqlalchemy中,如何进行记录的增删改查。
init_app.py代码不变:
# -*- coding = utf-8 -*-
from sqlalchemy import URL
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
url = URL.create(drivername="mysql", username='root', password='123', host='127.0.0.1', port=3306, database='alchemy')
engine = create_engine(url=url, echo=True, pool_size=10, max_overflow=30, pool_recycle=60 * 30)
Session = sessionmaker(bind=engine)
session = Session()models.py代码也不变:
# -*- coding = utf-8 -*-
from datetime import datetime
import sqlalchemy as db
from sqlalchemy.orm import declarative_base
from init_app import engine
# 模型类对象的基类,内部提供了数据库的基本操作以及共同方法
Model = declarative_base()
class Books(Model):
""" 书籍表 """
__tablename__ = "tb_books"
id = db.Column(db.Integer, primary_key=True, autoincrement=True, comment='主键ID')
title = db.Column(db.String(32), nullable=True, comment='书籍名称')
price = db.Column(db.Float, comment='书籍价格')
pub_date = db.Column(db.Date, default=datetime.now, comment='书籍出版日期')
publish = db.Column(db.String(32), nullable=True, comment='书籍出版社')
def __repr__(self):
return f"<{self.title}>"
class Users(Model): # 模型类类名可以按需指定,但必须指定Model基类,才会在后续的操作中通过sqlalchemy进行数据库迁移
""" 用户表 """
__tablename__ = "tb_users" # 必须这么指定该模型类在数据库中对应的表名
id = db.Column(db.Integer, primary_key=True, autoincrement=True, comment='主键ID')
name = db.Column(db.String(20), comment='用户名')
sex = db.Column(db.Boolean, default=True, comment='用户性别')
age = db.Column(db.SmallInteger, comment='用户年龄')
mobile = db.Column(db.BigInteger, comment='手机号')
email = db.Column(db.String(64), comment='邮箱')
pwd = db.Column(db.String(20), comment='密码')
classes = db.Column(name="class", type_=db.SMALLINT, comment='用户班级')
addr = db.Column(db.Text, comment='家庭住址')
status = db.Column(db.Boolean, default=1, comment='状态')
add_date = db.Column(db.Date, default=datetime.now, comment='添加日期')
birth_datetime = db.Column(db.DateTime, default=datetime.now, comment='出生时间')
def __repr__(self):
return f"<{self.name}>"
if __name__ == '__main__':
Model.metadata.create_all(engine)本章节后续所有的增删改查代码都在test.py中实现。
添加记录
test.py:
import string
import random
import faker # https://www.cnblogs.com/Neeo/articles/11316724.html
from datetime import datetime
from init_app import session
from models import Books, Users
fk = faker.Faker(locale='zh_CN')
""" 添加一条记录 """
# # 因为pubdate字段在模型类中,有默认值,所以,这里可以指定也可以不指定,不指定就以创建记录时的日期为准
# # 因为pubdate字段是Date类型,指定now,在添加到数据库中,会自动截取到日期,后面的时间不要
book1 = Books(title='红楼梦1', price=round(random.random() * 100, 2), pubdate=datetime.now(), publish='橘子出版社')
book2 = Books(title='红楼梦2', price=round(random.random() * 100, 2), publish='橙子出版社')
session.add(book1)
session.add(book2)
# 对于DML语句,必须进行commit才能真正的在数据库执行对应的语句
session.commit()
""" 添加多条记录 """
book_list = [
Books(
title=f'{fk.city()}旅游指南', price=round(random.random() * 100, 2),
pubdate=fk.date(pattern='%Y-%m-%d %H:%M:%S'), publish=f'{fk.city()}出版社'
)
for item in range(1, 21)
]
user_list = [
Users(
name=fk.name(), sex=random.choice([True, False]), age=random.randrange(20, 25), mobile=f'130{"".join(random.sample(string.digits, 8))}',
classes=random.randrange(300, 305), addr=fk.address(), status=random.choice([0, 1]),
add_date=fk.date(pattern='%Y-%m-%d %H:%M:%S'), birth_datetime=fk.date(pattern='%Y-%m-%d %H:%M:%S')
)
for i in range(1, 21)
]
session.add_all(book_list)
session.add_all(user_list)
session.commit()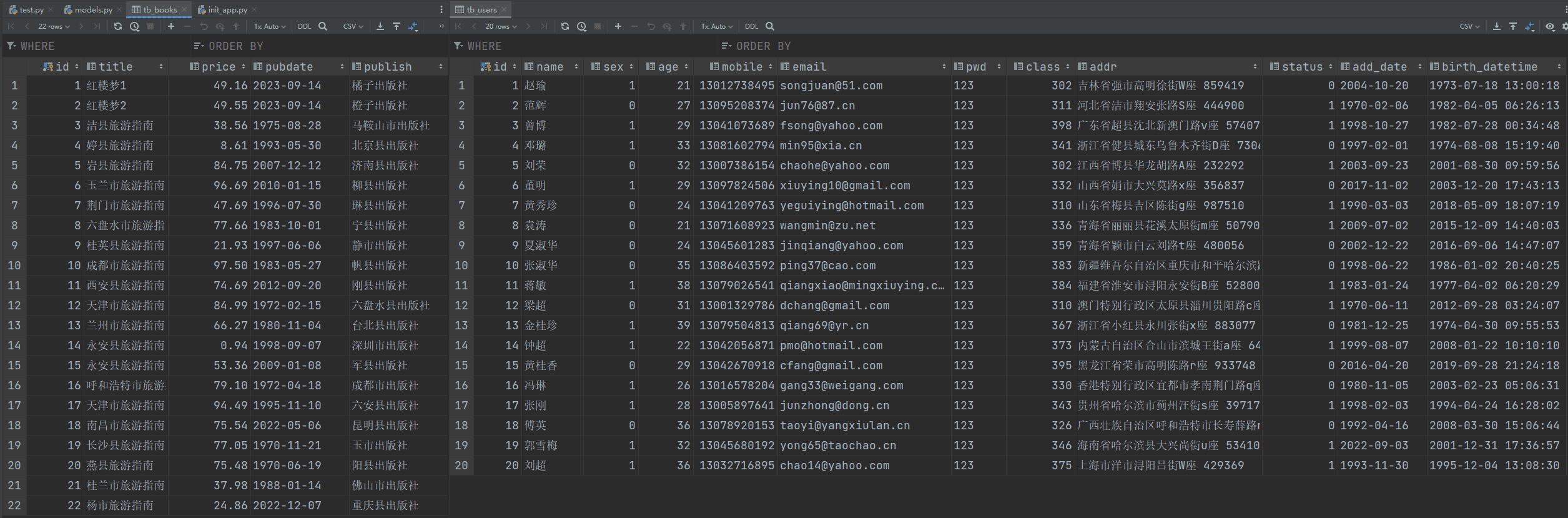
查询记录
查询一条记录:get和first
test.py:
from datetime import datetime
from init_app import session
from models import Books, Users
"""
查询单条记录:get
get 用于根据主键值获取一条,如果查不到数据,则返回None,查到结果则会被ORM底层使用当前模型类来进行实例化成模型对象
"""
book_obj = session.query(Books).get(ident=1) # sqlalchemy1.4版本这么用, 2.x也可以使用,但是有LegacyAPIWarning警告
print(book_obj) # <红楼梦1>
# sqlalchemy2.x版本这么用 session.get(模型类, 主键ID值)
book_obj = session.get(Books, ident=1) # 内部会将查询结果自动转为模型类对象
print(book_obj, book_obj.title) # <红楼梦1> 红楼梦1
"""
查询单条记录:first
first相当于select * from tb_books limit 1;
"""
book_obj = session.query(Books).first()
print(book_obj, book_obj.title) # <红楼梦1> 红楼梦1注意,这里查询操作,不需要commit。
查询多条记录:all
test.py:
from datetime import datetime
from init_app import session
from models import Books, Users
"""
查询多条记录:all
相当于select * from tb_books;
"""
book_obj_list = session.query(Books).all()
# 返回的结果是列表,列表中包含的是一个一个的模型类对象
print(book_obj_list) # [<红楼梦1>, <红楼梦2>, <洁县旅游指南>, <婷县旅游指南>, <岩县旅游指南>, <玉兰市旅游指南>, <荆门市旅游指南>, <六盘水市旅游指南>, <桂英县旅游指南>, <成都市旅游指南>, <西安县旅游指南>, <天津市旅游指南>, <兰州市旅游指南>, <永安县旅游指南>, <永安县旅游指南>, <呼和浩特市旅游指南>, <天津市旅游指南>, <南昌市旅游指南>, <长沙县旅游指南>, <燕县旅游指南>, <桂兰市旅游指南>, <杨市旅游指南>]
# 因为结果是个列表,那么你就可以对查询结果进行切片、截取等操作
# book_obj_list = session.query(Books).all()[0]
# book_obj_list = session.query(Books).all()[:5]精确查询:filter_by
test.py:
from datetime import datetime
from init_app import session
from models import Books, Users
"""
filter_by - 精确查询
filter_by是精确查询,仅支持值相等=号操作,不能使用大于、小于或不等于的操作一律不能使用
"""
# 仅使用filter_by拿到的结果是 <class 'sqlalchemy.orm.query.Query'> 对象
# book_objs = session.query(Books).filter_by(title='红楼梦1')
# print(type(book_objs)) # <class 'sqlalchemy.orm.query.Query'>
# 想要结果通常跟其它的与语句结合,比如查询所有符合条件的结果;查询符合条件的结果中的第一个
# book_objs = session.query(Books).filter_by(title='红楼梦1').all()
# print(book_objs) # [<红楼梦1>]
# book_obj = session.query(Books).filter_by(title='红楼梦1').first()
# print(book_obj) # <红楼梦1>
# 也可以跟多个条件
# book_objs = session.query(Books).filter_by(pubdate='2023-09-14', price=49.16).all()
# print(book_objs) # [<红楼梦1>]匹配查询:filter
test.py:
from datetime import datetime
from init_app import session
from models import Books, Users
"""
filter - 匹配查询
支持所有的运算符表达式,比filter精确查询要更强大
注意:
条件表达式中的字段名必须写上模型类名
filter中的判断相等必须使用==2个等号
"""
# # 单个条件
# book_objs = session.query(Books).filter(Books.pubdate == '2023-09-14').all()
# print(book_objs) # [<红楼梦1>, <红楼梦2>]
#
# # 单个条件
# book_objs = session.query(Books).filter(Books.pubdate == '2023-09-14').first()
# print(book_objs) # <红楼梦1>
# 单个条件,可以使用大于,小于
# book_objs = session.query(Books).filter(Books.price > 84.75).all()
# print(book_objs) # [<玉兰市旅游指南>, <成都市旅游指南>, <天津市旅游指南>, <天津市旅游指南>]
# book_objs = session.query(Books).filter(Books.price < 24.86).all()
# print(book_objs) # [<婷县旅游指南>, <桂英县旅游指南>, <永安县旅游指南>]
# book_objs = session.query(Books).filter(Books.price != 24.86).all()
# print(book_objs) # [<红楼梦1>, <红楼梦2>, <洁县旅游指南>, <婷县旅游指南>, <岩县旅游指南>, <玉兰市旅游指南>, <荆门市旅游指南>, <六盘水市旅游指南>, <桂英县旅游指南>, <成都市旅游指南>, <西安县旅游指南>, <天津市旅游指南>, <兰州市旅游指南>, <永安县旅游指南>, <永安县旅游指南>, <呼和浩特市旅游指南>, <天津市旅游指南>, <南昌市旅游指南>, <长沙县旅游指南>, <燕县旅游指南>, <桂兰市旅游指南>]
# # 直接跟多个条件,多个条件之间关系是and
# book_objs = session.query(Books).filter(Books.publish == '橘子出版社', Books.pubdate == "2023-09-14").all()
# print(book_objs) # [<红楼梦1>]and、or
test.py:
from datetime import datetime
from sqlalchemy import or_, and_, not_
from init_app import session
from models import Books, Users
""" or """
# or,查询书籍出版日期是 2023-09-14 或者 1975-08-28 的所有书籍
# book_objs = session.query(Books).filter(or_(
# Books.pubdate == '2023-09-14', # or中直接跟多个条件即可
# Books.pubdate == '1975-08-28',
# )).all()
# print(book_objs) # [<红楼梦1>, <红楼梦2>, <洁县旅游指南>]
""" and """
# and,查询书籍出版日期是 2023-09-14 且出版社是 橘子出版社 的所有书籍
# 下面两种写法都可以
# book_objs = session.query(Books).filter(and_( # 可以用and
# Books.pubdate == '2023-09-14',
# Books.publish == '橘子出版社',
# )).all()
# print(book_objs) # [<红楼梦1>]
#
# book_objs = session.query(Books).filter( # 或者直接写多个条件,多个条件本身也是and关系
# Books.pubdate == '2023-09-14',
# Books.publish == '橘子出版社',
# ).all()
# print(book_objs) # [<红楼梦1>]
""" and和or结合使用"""
# 查询 302 班 21 岁男生,或者 302 班 32 岁女生
# 下面两种方式都可以
# select * from tb_users where class = 302 and age = 21 and sex = 1 or class = 302 and age = 32 and sex = 0;
# user_objs = session.query(Users).filter(
# or_(
# and_(Users.classes == 302, Users.age == 21, Users.sex == 1),
# and_(Users.classes == 302, Users.age == 32, Users.sex == 0),
# )
# ).all()
# print(user_objs) # [<赵瑜>, <刘荣>]
# select * from tb_users where class = 302 and (age = 21 and sex = 1 or age = 32 and sex = 0);
# user_objs = session.query(Users).filter(
# and_(
# Users.classes == 302,
# or_(
# and_(Users.age == 21, Users.sex == 1),
# and_(Users.age == 32, Users.sex == 0),
# )
# )
# ).all()
# print(user_objs) # [<赵瑜>, <刘荣>]
# 来个多条件登录示例,允许手机号、用户名、邮箱三选一,然后结合密码进行的登录
while True:
user = input('请输入用户名/邮箱/手机号: ').strip() # 赵瑜 13012738495 songjuan@51.com
pwd = input('请输入密码: ').strip()
user_obj = session.query(Users).filter(
and_(
Users.pwd == pwd,
or_(Users.name == user, Users.mobile == user, Users.email == user)
)
).first()
if user_obj:
print('login successful')
else:
print('error')
"""
请输入用户名/邮箱/手机号: ad
请输入密码: 123
error
请输入用户名/邮箱/手机号: 赵瑜
请输入密码: 123
login successful
请输入用户名/邮箱/手机号: 13012738495
请输入密码: 123
login successful
请输入用户名/邮箱/手机号: songjuan@51.com
请输入密码: 123
login successful
"""in、not、取反
test.py:
from datetime import datetime
from sqlalchemy import or_, and_, not_
from init_app import session
from models import Books, Users
""" in """
# 别看in_不智能提示,但是可以使用
# book_objs = session.query(Books).filter(Books.id.in_([1, 2, 3])).all()
# print(book_objs) # [<红楼梦1>, <红楼梦2>, <洁县旅游指南>]
# book_objs = session.query(Books).filter(Books.price.in_([8.61, 84.75])).all()
# print(book_objs) # [<婷县旅游指南>, <岩县旅游指南>]
# book_objs = session.query(Books).filter(Books.pubdate.in_(["2023-09-14", "1997-06-06"])).all()
# print(book_objs) # [<红楼梦1>, <红楼梦2>, <桂英县旅游指南>]
# book_objs = session.query(Books).filter(Books.title.in_(["红楼梦1", '红楼梦2'])).all()
# print(book_objs) # [<红楼梦1>, <红楼梦2>]
""" not和in结合,实现not in """
# book_objs = session.query(Books).filter(not_(Books.id.in_([1, 2, 3]))).all()
# print(book_objs) # [<婷县旅游指南> ..... <杨市旅游指南>]
# book_objs = session.query(Books).filter(not_(Books.price.in_([8.61, 84.75]))).all()
# print(book_objs) # [<红楼梦1> .... <杨市旅游指南>]
# book_objs = session.query(Books).filter(not_(Books.pubdate.in_(["2023-09-14", "1997-06-06"]))).all()
# print(book_objs) # [<洁县旅游指南> ... <杨市旅游指南>]
# book_objs = session.query(Books).filter(not_(Books.title.in_(["红楼梦1", '红楼梦2']))).all()
# print(book_objs) # [<洁县旅游指南> ... <杨市旅游指南>]
""" ~取反,实现not in的效果 """
# book_objs = session.query(Books).filter(not_(Books.id.in_([1, 2, 3]))).all()
# print(book_objs) # [<婷县旅游指南> ..... <杨市旅游指南>]
#
# book_objs = session.query(Books).filter(~Books.id.in_([1, 2, 3])).all()
# print(book_objs) # [<婷县旅游指南> ..... <杨市旅游指南>]order_by
test.py:
from datetime import datetime
from sqlalchemy import or_, and_, not_
from init_app import session
from models import Books, Users
""" 查询所有数据并对结果进行排序 """
# # 降序排序
# book_objs = session.query(Books).order_by(Books.pubdate.desc()).all()
# print([(i.title, str(i.pubdate)) for i in book_objs]) # [('红楼梦1', '2023-09-14'), ('红楼梦2', '2023-09-14'), ('杨市旅游指南', '2022-12-07') ... ('燕县旅游指南', '1970-06-19')]
# # 升序排序
# book_objs = session.query(Books).order_by(Books.pubdate.asc()).all()
# print([(i.title, str(i.pubdate)) for i in book_objs]) # [('燕县旅游指南', '1970-06-19') ... ('红楼梦2', '2023-09-14')]
# # 对于多个排序字段,如下示例中,优先以日期进行升序排序,即默认是asc,可以省略不写,日期相同的,以id字段升序排序
# book_objs = session.query(Books).order_by(Books.pubdate.asc(), Books.id.asc()).all()
# book_objs = session.query(Books).order_by(Books.pubdate, Books.id).all()
# print([(i.id, i.title, str(i.pubdate)) for i in book_objs]) # [(20, '燕县旅游指南', '1970-06-19'), (19, '长沙县旅游指南', '1970-11-21') ... (1, '红楼梦1', '2023-09-14'), (2, '红楼梦2', '2023-09-14')]
#
# # 对于多个排序字段,如下示例中,优先以日期进行降序序排序,日期相同的,以id字段降序排序
# book_objs = session.query(Books).order_by(Books.pubdate.desc(), Books.id.desc()).all()
# print([(i.id, i.title, str(i.pubdate)) for i in book_objs]) # [(2, '红楼梦2', '2023-09-14'), (1, '红楼梦1', '2023-09-14') ... (19, '长沙县旅游指南', '1970-11-21'), (20, '燕县旅游指南', '1970-06-19')]
""" 先根据条件查询结果,对查询结果进行排序 """
# # 根据日期字段降序排序
# book_objs = session.query(Books).filter(Books.id.in_([1, 2, 3, 4, 5, 6])).order_by(Books.pubdate.desc()).all()
# print([(i.title, str(i.pubdate)) for i in book_objs]) # [('红楼梦1', '2023-09-14'), ('红楼梦2', '2023-09-14') ..... ('洁县旅游指南', '1975-08-28')]
#
# # 根据日期字段升序排序
# book_objs = session.query(Books).filter(Books.id.in_([1, 2, 3, 4, 5, 6])).order_by(Books.pubdate.asc()).all()
# print([(i.title, str(i.pubdate)) for i in book_objs]) # [('洁县旅游指南', '1975-08-28') .... ('红楼梦2', '2023-09-14')]
# # 根据id字段降序排序
# book_objs = session.query(Books).filter(Books.id.in_([1, 2, 3, 4, 5, 6])).order_by(Books.id.desc()).all()
# print([(i.title, str(i.pubdate)) for i in book_objs]) # [('玉兰市旅游指南', '2010-01-15'), ('岩县旅游指南', '2007-12-12'), ('婷县旅游指南', '1993-05-30'), ('洁县旅游指南', '1975-08-28'), ('红楼梦2', '2023-09-14'), ('红楼梦1', '2023-09-14')]
# # 根据id字段升序排序
# book_objs = session.query(Books).filter(Books.id.in_([1, 2, 3, 4, 5, 6])).order_by(Books.id.asc()).all()
# print([(i.title, str(i.pubdate)) for i in book_objs]) # [('红楼梦1', '2023-09-14'), ('红楼梦2', '2023-09-14'), ('洁县旅游指南', '1975-08-28'), ('婷县旅游指南', '1993-05-30'), ('岩县旅游指南', '2007-12-12'), ('玉兰市旅游指南', '2010-01-15')]imit、offset、slice
- limit:可以限制每次查询的时候只查询几条数据。
- offset:可以限制查找数据的时候过滤掉前面多少条。
- slice切片:可以对Query对象使用切片操作,来获取想要的数据。可以使用
slice(start,stop)方法来做切片操作。也可以使用[start:stop]的方式来进行切片操作。一般在实际开发中,中括号的形式是用得比较多的。
test.py:
from datetime import datetime
from sqlalchemy import or_, and_, not_
from init_app import session
from models import Books, Users
""" limit对结果条数进行限制 """
# select * from tb_users limit 3;
# user_objs = session.query(Users).limit(3).all()
# print(user_objs) # [<赵瑜-1>, <范辉-2>, <曾博-3>]
""" limit也可以跟order_by或者filter结合使用 """
# user_objs = session.query(Users).order_by(Users.age).limit(3).all()
# print(user_objs) # [<赵瑜-1>, <袁涛-8>, <钟超-14>]
""" limit结合offset """
# select * from tb_users limit 10, 3;
# limit和offset谁写前面谁写后面都一样
# user_objs = session.query(Users).limit(3).offset(10).all()
# print(user_objs) # [<蒋敏-11>, <梁超-12>, <金桂珍-13>]
#
# user_objs = session.query(Users).offset(10).limit(3).all()
# print(user_objs) # [<蒋敏-11>, <梁超-12>, <金桂珍-13>]
""" slice和切片 """
# 查询结果是列表的话,我们可以使用列表的切片对结果进一步处理
# 除此之外,也可以使用slice进行切片
# user_objs = session.query(Users).all()[2:5]
# print(user_objs) # [<曾博-3>, <邓璐-4>, <刘荣-5>]
#
# user_objs = session.query(Users).slice(2, 5).all()
# print(user_objs) # [<曾博-3>, <邓璐-4>, <刘荣-5>]like、between
test.py:
from datetime import datetime
from sqlalchemy import or_, and_, not_
from init_app import session
from models import Books, Users
""" limit对结果条数进行限制 """
# select * from tb_users limit 3;
# user_objs = session.query(Users).limit(3).all()
# print([f"{i.name}-{i.id}" for i in user_objs]) # ['赵瑜-1', '范辉-2', '曾博-3']
""" limit也可以跟order_by或者filter结合使用 """
# user_objs = session.query(Users).order_by(Users.age).limit(3).all()
# print([f"{i.name}-{i.id}" for i in user_objs]) # ['赵瑜-1', '袁涛-8', '钟超-14']
""" limit结合offset """
# select * from tb_users limit 10, 3;
# limit和offset谁写前面谁写后面都一样
# user_objs = session.query(Users).limit(3).offset(10).all()
# print([f"{i.name}-{i.id}" for i in user_objs]) # ['蒋敏-11', '梁超-12', '金桂珍-13']
# user_objs = session.query(Users).offset(10).limit(3).all()
# print([f"{i.name}-{i.id}" for i in user_objs]) # ['蒋敏-11', '梁超-12', '金桂珍-13']
""" slice和切片 """
# 查询结果是列表的话,我们可以使用列表的切片对结果进一步处理
# 除此之外,也可以使用slice进行切片
# user_objs = session.query(Users).all()[2:5]
# print([f"{i.name}-{i.id}" for i in user_objs]) # ['曾博-3', '邓璐-4', '刘荣-5']
#
# user_objs = session.query(Users).slice(2, 5).all()
# print([f"{i.name}-{i.id}" for i in user_objs]) # ['曾博-3', '邓璐-4', '刘荣-5']聚合分组
test.py:
from datetime import datetime
from sqlalchemy import or_, and_, not_
from sqlalchemy.sql import func # 聚合依赖func,需要提前导入
from init_app import session
from models import Books, Users
""" 分组查询group_by """
# 根据班级进行分组
# user_objs = session.query(
# Users.classes, # 根据班级进行分组
# func.count(Users.id) # 每组班级的数量
# ).group_by(Users.classes).all()
# print(user_objs) # [(302, 2), (311, 1) .... (346, 1), (375, 1)]
# 根据班级进行分组,并获取每个班级中的人数、最大年龄、最小年龄、平均年龄
# user_objs = session.query(
# Users.classes, # 根据班级进行分组
# func.count(Users.id), # 每个班级中的人数
# func.avg(Users.age), # 平均年龄
# func.min(Users.age), # 最小年龄
# func.max(Users.age), # 最大年龄
# func.sum(Users.age), # 总年龄
# ).group_by(Users.classes).all()
# print(user_objs) # [(302, 2, Decimal('26.5000'), 21, 32, Decimal('53')) .... (375, 1, Decimal('36.0000'), 36, 36, Decimal('36'))]
""" 分组查询group_by结合having对分组结果进行再次筛选 """
# 根据班级进行分组,并过滤出班级号大于390的班级,然后获取每个班级中的人数、最大年龄、最小年龄、平均年龄
# user_objs = session.query(
# Users.classes, # 根据班级进行分组
# func.count(Users.id), # 每个班级中的人数
# func.avg(Users.age), # 平均年龄
# func.min(Users.age), # 最小年龄
# func.max(Users.age), # 最大年龄
# func.sum(Users.age), # 总年龄
# ).group_by(Users.classes).having(Users.classes > 390).all()
# print(user_objs) # [(398, 1, Decimal('29.0000'), 29, 29, Decimal('29')), (395, 1, Decimal('29.0000'), 29, 29, Decimal('29'))]
# 筛选出组内成员年龄大于35岁的,然后获取每个班级中的人数、最大年龄、最小年龄、平均年龄
# user_objs = session.query(
# Users.classes, # 根据班级进行分组
# func.count(Users.id), # 每个班级中的人数
# func.avg(Users.age), # 平均年龄
# func.min(Users.age), # 最小年龄
# func.max(Users.age), # 最大年龄
# func.sum(Users.age), # 总年龄
# ).group_by(Users.classes).having(func.min(Users.age) > 35).all()
# print(user_objs) # [(384, 1, Decimal('38.0000'), 38, 38, Decimal('38')) ... (375, 1, Decimal('36.0000'), 36, 36, Decimal('36'))]
# 筛选出组内成员年龄大于35岁的且班级号大于380的,然后获取每个班级中的人数、最大年龄、最小年龄、平均年龄
user_objs = session.query(
Users.classes, # 根据班级进行分组
func.count(Users.id), # 每个班级中的人数
func.avg(Users.age), # 平均年龄
func.min(Users.age), # 最小年龄
func.max(Users.age), # 最大年龄
func.sum(Users.age), # 总年龄
).group_by(Users.classes).having(func.min(Users.age) > 35, Users.classes > 380).all()
print(user_objs) # [(384, 1, Decimal('38.0000'), 38, 38, Decimal('38'))]更新记录
test.py:
from datetime import datetime
from sqlalchemy import or_, and_, not_
from sqlalchemy.sql import func # 分组聚合依赖func,需要提前导入
from init_app import session
from models import Books, Users
"""更新数据方式1:通过更新对象属性进行更新"""
# obj = session.get(Users, 1)
# # 通过为指定属性复制的形式进行更新,你可以更新任意的属性
# obj.age += 1
# obj.classes = 311
# # 注意,必须commit才能更新成功
# session.commit()
# session.close()
"""更新数据方式2:通过update方法进行更新"""
# 先将符合条件的记录查询出来,然后进行批量更新,以字典的形式更新一个或多个字段值
session.query(Users).filter(Users.classes == 311).update({Users.age: Users.age + 1, Users.status: 0})
session.commit()
session.close()删除记录
test.py:
from datetime import datetime
from sqlalchemy import or_, and_, not_
from sqlalchemy.sql import func # 分组聚合依赖func,需要提前导入
from init_app import session
from models import Books, Users
"""删除数据方式1:先获取对象,然后再删除该对象"""
# obj = session.get(Users, 1)
# session.delete(obj)
# session.commit()
# session.close()
"""删除数据方式2:通过delete方法进行删除"""
# 先将符合条件的记录查询出来,然后进行批量删除
session.query(Users).filter(Users.age == 29).delete()
session.commit()
session.close()模型关联关系
首先是init_app.py:
# -*- coding = utf-8 -*-
from sqlalchemy import URL
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
url = URL.create(drivername="mysql", username='root', password='123', host='127.0.0.1', port=3306, database='alchemy')
engine = create_engine(
# mysqlclient + sqlalchemy 你这么写URL
url=url,
# echo=True,
pool_size=10,
max_overflow=30,
pool_recycle=60 * 30
)
Session = sessionmaker(bind=engine)
session = Session()一对一
注意:这里演示的是纯sqlalchemy的原生写法,不涉及到flask-sqlalchemy模块。
常见的业务:主表和详情表(用户、会员、学生、商品、文章、主机)。
关联属性定义在主表中(常用)
模型类关系的配置,在models.py中,且通过添加自定义查询方法,使其在查询时更加方便快捷,在查询部分将会体现出来。
from datetime import datetime
# sqlalchemy包导入好了常见的字段类型,我们这里直接导入即可,我为了少敲几个字,通过as语句起个简单的别名
import sqlalchemy as db
from sqlalchemy.dialects import mysql
from sqlalchemy.orm import relationship, backref, declarative_base
from init_app import engine
Model = declarative_base()
class User(Model):
""" 用户表 """
__tablename__ = "tb_user"
id = db.Column(db.Integer, primary_key=True, autoincrement=True, comment='主键ID')
name = db.Column(db.String(20), comment='用户名')
# user_backref是关联属性字段,它是模型类代码级别的关系声明,为了在orm中操作方便,但并不会在数据库表中真正的创建该字段
# relationship(
# "UserDetail", # 被关联的模型类类名
# uselist=False, # 因为是一对一关系,这里是拿到的外键记录对象也是唯一的,所以这里填写False
# backref='ubk' # 用于插入、反向查询的,值可以任意指定
# )
# 这么写可以
# user_backref = relationship("UserDetail", uselist=False, backref='ubk')
# 这么写也可以
user_backref = relationship("UserDetail", uselist=False, backref=backref('ubk', uselist=False))
@property
def get_dict1(self):
""" 返回当前表的普通字段,不包含关联属性的记录 """
return {'name': self.name}
@property
def get_dict2(self):
""" 返回包含关联属性的记录 """
return {
'name': self.name,
'detail': self.user_backref.get_dict1 if self.user_backref else None # 如果没有对应的记录返回None
}
def __repr__(self):
return f"<{self.name}-{self.id}>"
"""
create table tb_user
(
id int auto_increment comment '主键ID'
primary key,
name varchar(20) null comment '用户名'
);
"""
class UserDetail(Model):
""" 用户详情表 """
__tablename__ = "tb_user_detail"
id = db.Column(db.Integer, primary_key=True, autoincrement=True, comment='主键ID')
city = db.Column(db.String(20), comment='所在城市')
# 一对一关联关系中,外键关系字段一般声明在辅表中,且该字段会在数据库表中真正的创建该字段
# ForeignKey中必须填写真实的表名,然后跟上主键,固定写法
user_id = db.Column(db.Integer, db.ForeignKey('tb_user.id'), comment='用户表id')
@property
def get_dict1(self):
""" 返回当前表的普通字段,不包含外键字段对应的记录 """
return {'city': self.city, 'user_id': self.user_id}
@property
def get_dict2(self):
""" 返回包含外键字段对应的记录 """
return {
'city': self.city,
'user': self.ubk.get_dict1 if self.ubk else None # 如果没有对应的记录返回None
}
def __repr__(self):
return f"<{self.city}-{self.id}-{self.user_id}>"
"""
create table tb_user_detail
(
id int auto_increment comment '主键ID' primary key,
city varchar(20) null comment '所在城市',
addr varchar(20) null comment '住址',
user_id int null comment '用户表id',
constraint tb_user_detail_ibfk_1 foreign key (user_id) references tb_user (id)
);
create index user_id on tb_user_detail (user_id);
"""
if __name__ == '__main__':
Model.metadata.drop_all(engine)
Model.metadata.create_all(engine)直接运行这个models.py文件,就会在数据库中真正的把表创建出来。
一对一添加记录
init_app.py和models.py代码不变。
操作在test.py中,这里添加记录分为两种情况:
- 主表中已经存在了记录,但该记录并没有对应的详情表记录,这种情况下,为主表的这种记录添加对应的详情记录。
- 同时为主表和辅表添加记录,并将两个记录绑定一对一关系。
import faker # https://www.cnblogs.com/Neeo/articles/11316724.html
from init_app import session
from models import User, UserDetail
fk = faker.Faker(locale='zh_CN')
""" 一对一添加数据,方式1 """
# 假设主表User,已经有了一条记录,我们要为该记录添加对应的详情表记录,这样做
# 这段代码先执行
# user_obj = User(name=fk.name())
# session.add(user_obj)
# session.commit()
# 方式1
# 现在,要为这个id=1的记录,添加对应的详情表记录
# 先把user对象查出来在通过属性赋值的方式添加详情记录
# user = session.get(User, 1)
# # print(user)
# user.user_backref = UserDetail(city=fk.city())
# session.commit()
# 方式2
# 先创建一个User记录
# user_obj = User(name=fk.name())
# session.add(user_obj)
# session.commit()
# user_obj = session.get(User, 2)
# # print(user_obj)
# # 再创建详情表记录,同时指定外键字段的值
# detail = UserDetail(
# # 通过关联属性绑定外键关系
# # 左边的ubk是模型类中User表的relationship中指定的backref的值ubk
# # 右边的user_obj是被关联的模型类对象
# ubk=user_obj,
# city=fk.city()
# )
# session.add(detail)
# session.commit()
# 方式3
# # 先创建一个User记录
# user_obj = User(name=fk.name())
# session.add(user_obj)
# session.commit()
# user_obj = session.get(User, 3)
# # print(user_obj)
# detail = UserDetail(
# # 通过详情表的外键字段指定关系
# user_id=user_obj.id, # 必须是User模型类对象的id值,而不是对象本身
# city=fk.city()
# )
# session.add(detail)
# session.commit()
""" 一对一添加数据,方式2 """
# 同时为两张表添加记录并指定关系
# 下面两种写法底层实现是一致的
# user_obj = User(
# name=fk.name(),
# # 通过属性关联添加详情表的记录对象
# user_backref=UserDetail(city=fk.city()) # 详情表这里,外键字段user_id不用传值,内部会自动传值
# )
# session.add(user_obj)
# session.commit()
# detail_obj = UserDetail(
# city=fk.city(),
# # 通过关联属性绑定外键关系
# # 左边的ubk是模型类中User表的relationship中指定的backref的值ubk
# # 右边就是被关联的User模型类对象了
# ubk=User(name=fk.name()) # User模型类中的user_backref不用管,因为MySQL中的表中压根没这个字段,所以无需处理
# )
# session.add(detail_obj)
# session.commit()一对一查询操作
口诀:
- 正向查询按主表关联属性的字段名。
- 反向查询按主表关联属性中定义的backref的值。
init_app.py和models.py代码不变,操作在test.py中:
import faker # https://www.cnblogs.com/Neeo/articles/11316724.html
from init_app import session
from models import User, UserDetail
# fk = faker.Faker(locale='zh_CN')
""" 一对一查询记录,正向查询 """
# user_obj = session.get(User, 2)
# # 如果没有调用关联属性查询附加模型对象,则ORM不会执行查询关联模型的SQL语句
# print(user_obj.name) # 冯琴 查询普通字段正常返回结果
# # 真正的获取关联的记录,orm才会执行对应的SQL语句
# print(user_obj.user_backref) # <澳门市-2-2>
# print(user_obj.user_backref.city) # 澳门市
# # 通过搭配模型类中定义的查询方法,我们可以很方便的获取想要的被关联表中的记录
# user_obj = session.get(User, 2)
# # 不要关联关系的记录
# print(user_obj.get_dict1) # {'name': '冯琴'}
# # 获取关联关系的记录,如果有的话,返回字典,没有的话该外键字段的值是None
# print(user_obj.get_dict2) # {'name': '冯琴', 'detail': {'city': '澳门市', 'user_id': 2}}
""" 一对一查询记录,反向查询 """
# detail_obj = session.get(UserDetail, 2)
# # 如果没有调用关联属性查询附加模型对象,则ORM不会执行查询关联模型的SQL语句
# print(detail_obj.city) # 澳门市 查询普通字段正常返回结果
# print(detail_obj.user_id) # 2 外键字段的值这里直接获取的话,就是普通的数字,只不过是对应的记录的id值
# # 这个ubk属性是User表模型类中relationship中指定的backref的值ubk,拿到的是对应的模型类对象
# print(detail_obj.ubk) # <冯琴-2>
# print(detail_obj.ubk.name) # 冯琴
#
# # 通过搭配模型类中定义的查询方法,我们可以很方便的获取想要的被关联表中的记录
# # 不要关联关系的记录
# print(detail_obj.get_dict1) # {'city': '澳门市', 'user_id': 2}
# # 获取关联关系的记录,如果有的话,返回字典,没有的话该外键字段的值是None
# print(detail_obj.get_dict2) # {'city': '澳门市', 'user': {'name': '冯琴'}}一对一修改记录
init_app.py和models.py代码不变,操作在test.py中:
import faker # https://www.cnblogs.com/Neeo/articles/11316724.html
from init_app import session
from models import User, UserDetail
# fk = faker.Faker(locale='zh_CN')
""" 一对一修改记录 """
# # 以User表进行记录修改
# user_obj = session.get(User, 2)
# # print(user_obj)
# user_obj.name = '张开'
# # 通过关联属性字段进行关联表的记录修改
# user_obj.user_backref.city = '苏州'
# session.commit()
# # 以UserDetail表进行记录修改
# detail_obj = session.get(UserDetail, 2)
# # print(user_obj)
# detail_obj.city = '南京'
# # 通过模型类中User表的relationship中指定的backref的值ubk
# detail_obj.ubk.name = '张开2'
# session.commit()一对一删除记录
init_app.py和models.py代码不变。
操作在test.py中:
import faker # https://www.cnblogs.com/Neeo/articles/11316724.html
from init_app import session
from models import User, UserDetail
# fk = faker.Faker(locale='zh_CN')
""" 一对一删除记录 """
# # 如果要删除的User表的记录,没有对应的详情表记录,则可以直接删除,否则无法删除,会报错
# session.query(User).filter_by(id=1).delete()
# session.commit()
# # 对于有对应详情表的记录的User表记录的删除,要先删除该详情表记录,再删除自己表的记录
# user_obj = session.query(User).filter_by(id=2).first() # 先把User表记录查出来
# session.query(UserDetail).filter_by(id=user_obj.id).delete() # 再把User表对应的详情表记录删掉
# session.delete(user_obj) # 再删User表自己的记录
# session.commit()关联属性定义在辅表中(不常用)
来看下关联属性在辅表中定义的话,我们的增删改查如何处理。
模型类关系的配置,在models.py中,我这里调整型下一对一的关系处理部分代码:
from datetime import datetime
# sqlalchemy包导入好了常见的字段类型,我们这里直接导入即可,我为了少敲几个字,通过as语句起个简单的别名
import sqlalchemy as db
from sqlalchemy.dialects import mysql
from sqlalchemy.orm import relationship, declarative_base, backref
from init_app import engine
Model = declarative_base()
class User(Model):
""" 用户表 """
__tablename__ = "tb_user"
id = db.Column(db.Integer, primary_key=True, autoincrement=True, comment='主键ID')
name = db.Column(db.String(20), comment='用户名')
# 主表中原来的关系字段可以注释掉了
# user_backref = relationship("UserDetail", uselist=False, backref='ubk')
@property
def get_dict1(self):
""" 返回当前表的普通字段,不包含关联属性的记录 """
return {'name': self.name}
@property
def get_dict2(self):
""" 返回包含关联属性的记录 """
return {
'name': self.name,
'detail': self.ubk.get_dict1 if self.ubk else None # 如果没有对应的记录返回None
}
def __repr__(self):
return f"<{self.name}-{self.id}>"
"""
create table tb_user
(
id int auto_increment comment '主键ID' primary key,
name varchar(20) null comment '用户名'
);
"""
class UserDetail(Model):
""" 用户详情表 """
__tablename__ = "tb_user_detail"
id = db.Column(db.Integer, primary_key=True, autoincrement=True, comment='主键ID')
city = db.Column(db.String(20), comment='所在城市')
# 一对一关联关系中,外键关系字段一般声明在辅表中,且该字段会在数据库表中真正的创建该字段
# ForeignKey中必须填写真实的表名,然后跟上主键,固定写法
user_id = db.Column(db.Integer, db.ForeignKey('tb_user.id'), comment='用户表id')
# 关联属性字段,代码级别的字段,用于orm操作,不会在数据库表中真实创建的字段,盎然了backref的值写法跟在主表中声明不太一样
user_backref = relationship("User", uselist=False, backref=backref('ubk', uselist=False))
@property
def get_dict1(self):
""" 返回当前表的普通字段,不包含外键字段对应的记录 """
return {'city': self.city, 'user_id': self.user_id}
@property
def get_dict2(self):
""" 返回包含外键字段对应的记录 """
return {
'city': self.city,
'user': self.user_backref.get_dict1 if self.user_backref else None # 如果没有对应的记录返回None
}
def __repr__(self):
return f"<{self.city}-{self.id}-{self.user_id}>"
"""
create table tb_user_detail
(
id int auto_increment comment '主键ID' primary key,
city varchar(20) null comment '所在城市',
addr varchar(20) null comment '住址',
user_id int null comment '用户表id',
constraint tb_user_detail_ibfk_1 foreign key (user_id) references tb_user (id)
);
create index user_id on tb_user_detail (user_id);
"""
if __name__ == '__main__':
Model.metadata.drop_all(engine)
Model.metadata.create_all(engine)一对一添加记录
init_app.py和models.py代码不变。
操作在test.py中,这里添加记录分为两种情况:
- 主表中已经存在了记录,但该记录并没有对应的详情表记录,这种情况下,为主表的这种记录添加对应的详情记录。
- 同时为主表和辅表添加记录,并将两个记录绑定一对一关系。
import faker # https://www.cnblogs.com/Neeo/articles/11316724.html
from init_app import session
from models import User, UserDetail
fk = faker.Faker(locale='zh_CN')
""" 一对一添加数据,方式1 """
# # 假设主表User,已经有了一条记录,我们要为该记录添加对应的详情表记录,这样做
# # 这段代码先执行
# # user_obj = User(name=fk.name())
# # session.add(user_obj)
# # session.commit()
#
# # 方式1
# # 现在,要为这个id=1的记录,添加对应的详情表记录
# # 先把user对象查出来在通过属性赋值的方式添加详情记录
# user = session.get(User, 1)
# # print(user)
# # 通过User表点在辅表UserDetail中定义的关联关系的backref的值进行添加详情记录
# user.ubk = UserDetail(city=fk.city())
# session.commit()
# # 方式2
# # 先创建一个User记录
# user_obj = User(name=fk.name())
# session.add(user_obj)
# session.commit()
# user_obj = session.get(User, 2)
# print(user_obj)
# # 再创建详情表记录,同时指定外键字段的值
# detail = UserDetail(
# # 通过关联属性绑定外键关系
# # 左边的user_backref是模型类中UserDetail表的关联关系的字段名
# # 右边的user_obj是被关联的模型类对象
# user_backref=user_obj,
# city=fk.city()
# )
# session.add(detail)
# session.commit()
# # 方式3
# # 先创建一个User记录
# user_obj = User(name=fk.name())
# session.add(user_obj)
# session.commit()
# user_obj = session.get(User, 3)
# # print(user_obj)
# detail = UserDetail(
# # 通过详情表的外键字段指定关系
# user_id=user_obj.id, # 必须是User模型类对象的id值,而不是对象本身
# city=fk.city()
# )
# session.add(detail)
# session.commit()
""" 一对一添加数据,方式2 """
# # 同时为两张表添加记录并指定关系
# # 下面两种写法底层实现是一致的
# user_obj = User(
# name=fk.name(),
# # ubk是UserDetail模型类的关联关系字段中的relationship中的backref的值
# ubk=UserDetail(city=fk.city()) # 详情表这里,外键字段user_id不用传值,内部会自动传值
# )
# session.add(user_obj)
# session.commit()
# detail_obj = UserDetail(
# city=fk.city(),
# # 通过关联属性绑定外键关系
# # 左边的user_backref是模型类中UserDetail表的关联关系的字段名
# # 右边就是被关联的User模型类对象了
# user_backref=User(name=fk.name())
# )
# session.add(detail_obj)
# session.commit()一对一查询操作
口诀:
- 正向查询按辅表关联属性的backref的值。
- 反向查询按附表关联属性的字段名。
init_app.py和models.py代码不变,操作在test.py中:
import faker # https://www.cnblogs.com/Neeo/articles/11316724.html
from init_app import session
from models import User, UserDetail
# fk = faker.Faker(locale='zh_CN')
""" 一对一查询记录,正向查询 """
# user_obj = session.get(User, 2)
# # 如果没有调用关联属性查询附加模型对象,则ORM不会执行查询关联模型的SQL语句
# print(user_obj.name) # 冯琴 查询普通字段正常返回结果
# # 真正的获取关联的记录,orm才会执行对应的SQL语句
# print(user_obj.ubk) # <澳门市-2-2>
# print(user_obj.ubk.city) # 澳门市
# # 通过搭配模型类中定义的查询方法,我们可以很方便的获取想要的被关联表中的记录
# user_obj = session.get(User, 2)
# # 不要关联关系的记录
# print(user_obj.get_dict1) # {'name': '冯琴'}
# # 获取关联关系的记录,如果有的话,返回字典,没有的话该外键字段的值是None
# print(user_obj.get_dict2) # {'name': '冯琴', 'detail': {'city': '澳门市', 'user_id': 2}}
""" 一对一查询记录,反向查询 """
# detail_obj = session.get(UserDetail, 2)
# # 如果没有调用关联属性查询附加模型对象,则ORM不会执行查询关联模型的SQL语句
# print(detail_obj.city) # 澳门市 查询普通字段正常返回结果
# print(detail_obj.user_id) # 2 外键字段的值这里直接获取的话,就是普通的数字,只不过是对应的记录的id值
# # 这个ubk属性是User表模型类中relationship中指定的backref的值ubk,拿到的是对应的模型类对象
# print(detail_obj.user_backref) # <冯琴-2>
# print(detail_obj.user_backref.name) # 冯琴
#
# # 通过搭配模型类中定义的查询方法,我们可以很方便的获取想要的被关联表中的记录
# # 不要关联关系的记录
# print(detail_obj.get_dict1) # {'city': '澳门市', 'user_id': 2}
# # 获取关联关系的记录,如果有的话,返回字典,没有的话该外键字段的值是None
# print(detail_obj.get_dict2) # {'city': '澳门市', 'user': {'name': '冯琴'}}一对一修改记录
init_app.py和models.py代码不变,操作在test.py中:
import faker # https://www.cnblogs.com/Neeo/articles/11316724.html
from init_app import session
from models import User, UserDetail
# fk = faker.Faker(locale='zh_CN')
""" 一对一修改记录 """
# 以User表进行记录修改
user_obj = session.get(User, 2)
# print(user_obj)
user_obj.name = '张开'
# 通过关联属性字段进行关联表的记录修改
user_obj.ubk.city = '苏州'
session.commit()
# 以UserDetail表进行记录修改
detail_obj = session.get(UserDetail, 3)
# print(user_obj)
detail_obj.city = '南京'
# user_backref是模型类中关联关系字段名
detail_obj.user_backref.name = '张开2'
session.commit()一对一删除记录
init_app.py和models.py代码不变。
操作在test.py中。
import faker # https://www.cnblogs.com/Neeo/articles/11316724.html
from init_app import session
from models import User, UserDetail
# fk = faker.Faker(locale='zh_CN')
""" 一对一删除记录 """
# # 如果要删除的User表的记录,没有对应的详情表记录,则可以直接删除,否则无法删除,会报错
# session.query(User).filter_by(id=1).delete()
# session.commit()
# # 对于有对应详情表的记录的User表记录的删除,要先删除该详情表记录,再删除自己表的记录
# user_obj = session.query(User).filter_by(id=2).first() # 先把User表记录查出来
# session.query(UserDetail).filter_by(id=user_obj.id).delete() # 再把User表对应的详情表记录删掉
# session.delete(user_obj) # 再删User表自己的记录
# session.commit()一对多
一对多或者多对一说的都是一回事儿。
常见业务:商品分类和商品、文章分类和文章、班级与学生、部门与员工、角色与会员、订单与订单详情、用户与收货地址。
首先init_app.py代码不变:
# -*- coding = utf-8 -*-
from sqlalchemy import URL
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
url = URL.create(drivername="mysql", username='root', password='123', host='127.0.0.1', port=3306, database='alchemy')
engine = create_engine(
# mysqlclient + sqlalchemy 你这么写URL
url=url,
# echo=True,
pool_size=10,
max_overflow=30,
pool_recycle=60 * 30
)
Session = sessionmaker(bind=engine)
session = Session()关联属性定义在一的一方中,外键字段定义在多的一方中(常用)
init_app.py代码不变,调整models.py文件:
from datetime import datetime
# sqlalchemy包导入好了常见的字段类型,我们这里直接导入即可,我为了少敲几个字,通过as语句起个简单的别名
import sqlalchemy as db
from sqlalchemy.dialects import mysql
from sqlalchemy.orm import relationship, declarative_base, backref
from init_app import engine
Model = declarative_base()
class User(Model):
""" 用户表 """
__tablename__ = "tb_user"
id = db.Column(db.Integer, primary_key=True, autoincrement=True, comment='主键ID')
name = db.Column(db.String(20), comment='用户名')
# 关联属性字段通常定义在一对多中一的一方
user_backref = relationship("UserAddress", uselist=True, backref="ubk", lazy='dynamic')
@property
def get_dict1(self):
""" 返回当前表的普通字段,不包含关联属性的记录 """
return {'name': self.name}
@property
def get_dict2(self):
""" 返回包含关联属性的记录 """
return {
'name': self.name,
'detail': self.ubk.get_dict1 if self.ubk else None # 如果没有对应的记录返回None
}
def __repr__(self):
return f"<{self.name}-{self.id}>"
"""
create table tb_user
(
id int auto_increment comment '主键ID' primary key,
name varchar(20) null comment '用户名'
);
"""
class UserAddress(Model):
""" 用户收货地址表 """
__tablename__ = "tb_user_address"
id = db.Column(db.Integer, primary_key=True, autoincrement=True, comment='主键ID')
province = db.Column(db.String(50), comment="省份")
city = db.Column(db.String(20), comment='城市')
# 外键字段会在数据库空中真实创建,一般外键字段推荐创建在多的模型类中
# 可以这么写
# user_id = db.Column(db.Integer, db.ForeignKey(User.id), comment='用户表id')
# 也可以这么写
user_id = db.Column(db.Integer, db.ForeignKey('tb_user.id'), comment='用户表id')
@property
def get_dict1(self):
""" 返回当前表的普通字段,不包含关联属性的记录 """
return {'name': self.name}
@property
def get_dict2(self):
""" 返回包含关联属性的记录 """
if self.user_backref:
addr = [i.get_dict1 for i in self.user_backref.all()]
else:
addr = None
return {'name': self.name, 'address': addr}
def __repr__(self):
return f"<{self.city}-{self.id}-{self.user_id}>"
"""
create table tb_user_address
(
id int auto_increment comment '主键ID' primary key,
province varchar(50) null comment '省份',
city varchar(20) null comment '城市',
user_id int null comment '用户表id',
constraint tb_user_address_ibfk_1 foreign key (user_id) references tb_user (id)
);
create index user_id on tb_user_address (user_id);
"""
if __name__ == '__main__':
Model.metadata.drop_all(engine)
Model.metadata.create_all(engine)直接运行这个models.py文件,就会在数据库中真正的把表创建出来。
解释下这行代码:
user_backref = relationship("UserAddress", uselist=True, backref="ubk", lazy='dynamic')- relationship描述了User表和UserAddress的关系,这个字段并不会在数据表中真正的创建该字段,只是方便orm的操作。
"UserAddress"是多的一方的模型类对象。uselist=True声明了多的一方的记录会有多个。backref="ubk"用于将来的orm操作中的"别名"。lazy='dynamic'决定了sqlalchemy什么时候执行读取关联模型的SQL语句,它的值有这几种:lazy='subquery',查询当前数据模型时,采用子查询(subquery),把外键模型的属性也同时查询出来了。lazy=True或lazy='select',查询当前数据模型时,不会把外键模型的数据查询出来,只有操作到外键关联属性时,才进行连表查询数据[执行SQL。lazy='dynamic',查询当前数据模型时,不会把外键模型的数据立刻查询出来,只有操作到外键关联属性并操作外键模型具体字段时,才进行连表查询数据[执行SQL。- 常用的lazy选项:
dynamic和select。
一对多添加记录
import faker # https://www.cnblogs.com/Neeo/articles/11316724.html
from init_app import session
from models import User, UserAddress
fk = faker.Faker(locale='zh_CN')
""" 一对多添加记录,User表的某个用户存在的,为它添加多个收获地址 """
# # 先搞出来一个用户
# user_obj = User(name=fk.name())
# session.add(user_obj)
# session.commit()
# # 为这个用户添加多个收货地址
# user_obj = session.get(User, 1)
# # 通过关联属性字段名添加多个收货地址
# user_obj.user_backref = [
# UserAddress(province=fk.province(), city=fk.city())
# for i in range(2)
# ]
# session.commit()
""" 一对多添加记录,也可以同时添加用户和收货地址 """
# user_obj = User(
# name=fk.name(),
# user_backref=[
# UserAddress(province=fk.province(), city=fk.city())
# for i in range(2)
# ]
# )
# session.add(user_obj)
# session.commit()
""" 一对多添加记录,添加一个用户收货地址记录,同时添加一个用户记录 """
# 但这样只能添加一个收货地址
# addr_obj = UserAddress(
# province=fk.province(), city=fk.city(),
# ubk=User(name=fk.name())
# )
# session.add(addr_obj)
# session.commit()
# 为同一个用户添加多个收货地址
""" 一对多添加记录,为同一个用户添加多个收货地址 """
# # 写法1,通过关联属性和模型类对象的形式
# user_obj = User(name=fk.name())
# addr_list = [
# UserAddress(
# province=fk.province(), city=fk.city(),
# ubk=user_obj
# )
# for i in range(2)
# ]
# session.add_all(addr_list)
# session.commit()
# # 写法2,通过外键字段赋值的形式
# 先把用户记录创建出来
# user_obj = User(name=fk.name())
# session.add(user_obj)
# session.commit()
# 然后找到新添加记录的ID
# user_obj = session.get(User, 4)
# addr_list = [
# UserAddress(
# province=fk.province(), city=fk.city(),
# user_id=user_obj.id # 循环创建模型类对象时,指定同一个用户,达到为一个用户添加多个收货地址的目的
# )
# for i in range(2)
# ]
# session.add_all(addr_list)
# session.commit()一对多查询记录
口诀:
- 正向查询按主表关联属性的字段名。
- 反向查询按主表关联属性中定义的backref的值。
init_app.py和models.py代码不变,操作在test.py中:
import faker # https://www.cnblogs.com/Neeo/articles/11316724.html
from init_app import session
from models import User, UserAddress
fk = faker.Faker(locale='zh_CN')
""" 一对多查询记录,正向查询,从一查多,根据关联属性字段名查询对应的数据 """
# # 查询用户对象,并且根据用户对象查询他的所有的收货地址
# user_obj = session.get(User, 1)
# print(user_obj.name) # 杨文
# print(user_obj.user_backref) # 返回的是SQL语句,但该SQL语句并没有执行
# print(user_obj.user_backref.all()) # [<雪市-1-1>, <大冶县-2-1>]
# # print(user_obj.user_backref[0]) # <雪市-1-1>
# print(user_obj.get_dict1) # {'name': '杨文'}
# print(user_obj.get_dict2) # {'name': '杨文', 'address': [{'city': '雪市', 'user_id': 1, 'province': '黑龙江省'}, {'city': '大冶县', 'user_id': 1, 'province': '新疆维吾尔自治区'}]}
""" 一对多查询记录,反向向查询,从多查一,根据关联属性的backref的值查询主表记录 """
# # 查询某个地址
# address_obj = session.get(UserAddress, 1)
# print(address_obj.city)
# # 根据某个地址查询该地址所属的用户
# print(address_obj.ubk)
# # 甚至再根据所属用户点关联属性字段,能查找到该用户的所有的地址
# print(address_obj.ubk.user_backref.all())
# print(address_obj.get_dict1) # {'city': '雪市', 'user_id': 1, 'province': '黑龙江省'}
# print(address_obj.get_dict2) # {'city': '雪市', 'province': '黑龙江省', 'user': {'name': '杨文'}}关于lazy的值
我们这里对lazy的值的不同,来看下底层SQL的执行情况。
init_app.py代码不变,通过更改models.py中的lazy值,在test.py中查看查询的底层SQL的执行情况:
import faker # https://www.cnblogs.com/Neeo/articles/11316724.html
from init_app import session
from models import User, UserAddress
fk = faker.Faker(locale='zh_CN')
"""
当模型类中,lazy的值是'dynamic'时,只有真正的需要访问辅表时,才会触发查询辅表的SQL语句
class User(Model):
# 关联属性字段通常定义在一对多中一的一方
user_backref = relationship("UserAddress", uselist=True, backref="ubk", lazy='dynamic')
注意,可以通过设置init_app中的echo=True来观察输出日志
"""
# user_obj = session.get(User, 1)
# # print(user_obj.name) # 这么写不会触发查询辅表的SQL语句
# user_obj.user_backref # 这么写不会触发查询辅表的SQL语句
# 下面几种情况都是要值,才会触发查询辅表的SQL语句
# print(user_obj.user_backref.all()) # [<雪市-1-1>, <大冶县-2-1>]
# print(user_obj.user_backref[0]) # <雪市-1-1>
"""
当模型类中,lazy的值是'subquery'时,只有真正的需要访问辅表时,才会触发查询辅表的SQL语句
class User(Model):
# 关联属性字段通常定义在一对多中一的一方
user_backref = relationship("UserAddress", uselist=True, backref="ubk", lazy='subquery')
注意,可以通过设置init_app中的echo=True来观察输出日志
"""
# # 写get的时候,已经触发查询辅表的SQL语句了,如果业务开发中,没有用到辅表的数据,这个辅表查询操作就是在浪费资源
# user_obj = session.get(User, 1)
# print(user_obj.name)
# # print(user_obj.user_backref.all()) # 因为已经拿到了辅表的数据,这里不需要点all了
# print(user_obj.user_backref) # [<雪市-1-1>, <大冶县-2-1>]
# print(user_obj.user_backref[0]) # <雪市-1-1>
"""
当模型类中,lazy的值是'select'时,只有真正的需要访问辅表时,才会触发查询辅表的SQL语句
class User(Model):
# 关联属性字段通常定义在一对多中一的一方
user_backref = relationship("UserAddress", uselist=True, backref="ubk", lazy='select')
注意,可以通过设置init_app中的echo=True来观察输出日志
"""
# # 写get的时候,只执行select主表的sql,不执行查询对应辅表的语句
# user_obj = session.get(User, 1)
# print(user_obj.name) # 只执行select主表的,不执行查询对应辅表的语句
# print(user_obj.user_backref.all()) # 查询对应辅表的语句,但不需要点all就能获取到数据,点all的话会报错
# print(user_obj.user_backref) # [<雪市-1-1>, <大冶县-2-1>]
# print(user_obj.user_backref[0]) # <雪市-1-1>
"""
当模型类中,lazy的值是True时,只有真正的需要访问辅表时,才会触发查询辅表的SQL语句
class User(Model):
# 关联属性字段通常定义在一对多中一的一方
user_backref = relationship("UserAddress", uselist=True, backref="ubk", lazy=True)
注意,可以通过设置init_app中的echo=True来观察输出日志
"""
# # 写get的时候,只执行select主表的sql,不执行查询对应辅表的语句
# user_obj = session.get(User, 1)
# print(user_obj.name) # 只执行select主表的,不执行查询对应辅表的语句
# print(user_obj.user_backref.all()) # 查询对应辅表的语句,但不需要点all就能获取到数据,点all的话会报错
# print(user_obj.user_backref) # [<雪市-1-1>, <大冶县-2-1>]
# print(user_obj.user_backref[0]) # <雪市-1-1>记得操作完,再把lazy值改为dynamic。
一对多更新记录
init_app.py和models.py代码不变,操作在test.py中:
import faker # https://www.cnblogs.com/Neeo/articles/11316724.html
from init_app import session
from models import User, UserAddress
fk = faker.Faker(locale='zh_CN')
"""
一对多更新记录,通过主表操作更新关联的辅表记录
"""
# 相当于重新添加了两个收货地址,原来的所有绑定的收货地址都会取消绑定,也就是UserAddress表的user_id都是null了
# user_obj = session.get(User, 1)
# user_obj.name = '张开'
# user_obj.user_backref = [
# UserAddress(province=fk.province(), city=fk.city())
# for i in range(2)
# ]
# session.commit()
# # 原有地址不变的基础上,再添加一个或者多个新的收货地址
# user_obj = session.get(User, 1)
# user_obj.name = '张开'
# # 添加一个新的收货地址
# # user_obj.user_backref.add(UserAddress(province=fk.province(), city=fk.city()))
# # 添加多个新的收货地址
# user_obj.user_backref.add_all([UserAddress(province=fk.province(), city=fk.city()) for i in range(2)])
# session.commit()
"""
一对多更新记录,通过辅表表操作更新关联用户
"""
# # 先把被绑定的用户对象查询出来,如果该地址已有绑定的用户,那么执行下面代码则会更新绑定关系
# user_obj = session.get(User, 1)
# addr_obj = session.get(UserAddress, 1)
# # print(addr_obj.ubk) # None 没有绑定用户
# # 通过关联属性的backref值为收货地址绑定用户
# addr_obj.ubk = user_obj
# session.commit()
# # 用下面的方式也可以
# user_obj = session.get(User, 2)
# addr_obj = session.get(UserAddress, 2)
# # print(addr_obj.ubk) # None 没有绑定用户
# # 通过关联属性的backref值为收货地址绑定用户
# addr_obj.user_id = user_obj.id
# session.commit()一对多删除记录
init_app.py和models.py代码不变,操作在test.py中:
import faker # https://www.cnblogs.com/Neeo/articles/11316724.html
from init_app import session
from models import User, UserAddress
fk = faker.Faker(locale='zh_CN')
"""
一对多删除记录,删除主表记录
"""
# # 要删除的用户没有收货地址的,直接删除
# user_obj = session.get(User, 5)
# print(user_obj.user_backref.all()) # []
# session.delete(user_obj)
# session.commit()
#
# # 要删除的用户有收货地址,也可以直接删除,但是收货地址表中的对应的记录不会删除,只是其中的user_id变为null
# user_obj = session.get(User, 4)
# print(user_obj.user_backref.all()) # [<建军市-6-4>, <阜新县-7-4>]
# session.delete(user_obj)
# session.commit()
"""
一对多删除记录,删除辅表记录
"""
# # 无论要删除的收货地址是否有绑定用户,都可以直接删除
# addr_obj = session.get(UserAddress, 1)
# print(addr_obj.ubk) # <张红-2>
# session.delete(addr_obj)
#
# session.commit()
# addr_obj = session.get(UserAddress, 6)
# print(addr_obj.ubk) # None
# session.delete(addr_obj)
# session.commit()多对多
多对多的业务场景也非常的广泛:
- 用户收藏文章,一个用户可以收藏多篇文章,一篇文章可以被多个用户收藏。
- 书籍与作者的关系,一个作业可以写多本书,一本书也可以由多个作者共同完成。
sqlalchemy中,对于多对多的处理,通常由以下几种处理方式:
- 第一种就是通过db.Table创建第三张表来进行多对多的关联关系。
- 第二种就是通过第三张表,以模型类的形式来进行多对多的关联关系。
- 上面两种第二种用的多一些,区别的话,我们在代码示例中进行讲解。
- 再有就是也是通过创建第三张表,但是这个表跟多对多的两张表在数据库层面没有关联关系,而是代码级别设计的关联关系,就是为了提高上面两种方式会真正的创建相关的外键约束,导致性能下降。
我们一起来看看都是怎么玩的吧。
接下来的示例中,我将创建用户表和课程表,两张表,他们的的关系是一个用户可以购买多个课程,一个课程也可以被多个用户购买,所以需要进行第三张表来处理多对多的关联关系。
基于db.Table实现多对多的关联关系
init_app.py文件代码不变,我们调整models.py文件:
from datetime import datetime
# sqlalchemy包导入好了常见的字段类型,我们这里直接导入即可,我为了少敲几个字,通过as语句起个简单的别名
import sqlalchemy as db
from sqlalchemy.dialects import mysql
from sqlalchemy.orm import relationship, declarative_base, backref
from init_app import engine
Model = declarative_base()
# User表和Course表的多对多的第三张表建立关联关系如下
# 该第三张表会在数据库中真正的创建出来
user_mtm_course = db.Table(
"tb_user_mtm_course", # 第一个参数指定第三张表自己的表名
# 第二个参数,必须和User和Course表共用同一个Model基类,也就是公用同一个基类中的metadata元信息,
# 这样写,后续才能通过Model.metadata.create_all(engine)创建出来这个第三张表,当然也就可以通过Model.metadata.drop_all(engine)来删除这个表了
Model.metadata,
# 下面定义的id字段是第三张表自己的主键ID
db.Column('id', db.Integer, primary_key=True, autoincrement=True, comment='主键ID'),
# 下面定义的uid和cid是多对多关系的两个字段,ForeignKey中必须填写真实数据库中表的名字,然后点主键ID
db.Column("uid", db.Integer, db.ForeignKey("tb_user.id"), comment="用户ID"),
db.Column("cid", db.Integer, db.ForeignKey("tb_course.id"), comment="课程ID"),
# 下面的额外的字段,但当前字段定义在这里,orm中无法操作,这里写上这个字段也就是让你看看,数据能存储,但用不了
db.Column("created_time", db.DateTime, default=datetime.now, comment="购买时间")
)
"""
create table tb_user_mtm_course
(
id int auto_increment comment '主键ID' primary key,
uid int null comment '用户ID',
cid int null comment '课程ID',
created_time datetime null comment '购买时间',
constraint tb_user_mtm_course_ibfk_1 foreign key (uid) references tb_user (id),
constraint tb_user_mtm_course_ibfk_2 foreign key (cid) references tb_course (id)
);
create index cid on tb_user_mtm_course (cid);
create index uid on tb_user_mtm_course (uid);
"""
class User(Model):
""" 用户表 """
__tablename__ = "tb_user"
id = db.Column(db.Integer, primary_key=True, autoincrement=True, comment='主键ID')
name = db.Column(db.String(20), comment='用户名')
money = db.Column(db.Numeric(10, 2), default=0.0, comment="钱包")
# 外键字段定义在User表中,也可以定义在Course表中,二选一即可,反正不会在数据库表中真实的创建该字段
# 当你想获取某个用户购买的所有的课程时,直接用户对象点course_list,也就是通过点外键字段实现
# 当你想获取某门课程的所有购买用户时,直接课程对象点user_list,通过backref的值实现
# 有了secondary的值必须是第三张表的
course_list = relationship("Course", secondary=user_mtm_course, backref="user_list", lazy="dynamic")
@property
def get_dict1(self):
""" 返回当前表的普通字段,不包含关联属性的记录 """
return {'name': self.name, 'money': float(self.money)}
@property
def get_dict2(self):
""" 返回包含关联属性的记录 """
if self.course_list:
course_list = [i.get_dict1 for i in self.course_list.all()]
else:
course_list = None
return {'name': self.name, 'course_list': course_list}
def __repr__(self):
return f"<{self.name}-{self.id}-{self.money}>"
"""
create table tb_user
(
id int auto_increment comment '主键ID' primary key,
name varchar(20) null comment '用户名',
money decimal(10, 2) null comment '钱包'
);
"""
class Course(Model):
""" 课程表 """
__tablename__ = "tb_course"
id = db.Column(db.Integer, primary_key=True, autoincrement=True, comment='主键ID')
name = db.Column(db.String(20), comment='课程名称')
price = db.Column(db.Numeric(10, 2), default=0.0, comment="课程价格")
# 如果外键字段定义在Course中,就参照下面的写法,当然了,你要注释掉User中的外键字段,两个表写到其中一个表中就行了
# 当你想获取某个用户购买的所有的课程时,直接用户对象点course_list,通过backref的值实现
# 当你想获取某门课程的所有购买用户时,直接课程对象点user_list,也就是通过点外键字段实现
# student_list = relationship("Course", secondary=user_mtm_course, backref="course_list", lazy="dynamic")
@property
def get_dict1(self):
""" 返回当前表的普通字段,不包含外键字段对应的记录 """
return {'name': self.name, 'price': float(self.price)}
@property
def get_dict2(self):
""" 返回包含外键字段对应的记录 """
if self.user_list:
user_list = [i.get_dict1 for i in self.user_list]
else:
user_list = None
return {
'name': self.name, 'price': float(self.price),
'user': user_list
}
def __repr__(self):
return f"<{self.name}-{self.id}-{self.price}>"
"""
create table tb_course
(
id int auto_increment comment '主键ID' primary key,
name varchar(20) null comment '课程名称',
price decimal(10, 2) null comment '课程价格'
);
"""
if __name__ == '__main__':
# 如果出现删不掉表的情况,大概率是因为外键约束,那你就手动删除外键关联的表就行了
Model.metadata.drop_all(engine)
Model.metadata.create_all(engine)直接运行这个models.py文件,就会在数据库中真正的把三张表创建出来了。
多对多添加数据
init_app.py和models.py代码不变,操作在test.py中:
import faker # https://www.cnblogs.com/Neeo/articles/11316724.html
from init_app import session
from models import User, Course
fk = faker.Faker(locale='zh_CN')
"""
多对多添加记录
分别添加用户和课程记录,不涉及多对多关联关系
"""
# 添加用户和课程记录
# session.add(User(name=fk.name()))
# session.add(Course(name=f'张开带你玩转{fk.province()}'))
# session.commit()
"""
多对多添加记录
添加一个用户,同时为该用户添加三个购买课程记录
SQL创建过程是这样的:
1. 先创建出来两个课程记录
INSERT INTO tb_course (name, price) VALUES (%s, %s) [generated in 0.00010s] ('张开带你玩转陕西省', 0.0)
INSERT INTO tb_course (name, price) VALUES (%s, %s) [cached since 0.001819s ago] ('张开带你玩转云南省', 0.0)
2. 创建用户表记录
INSERT INTO tb_user (name, money) VALUES (%s, %s) [generated in 0.00008s] ('潘玉兰', 0.0)
3. 创建第三张表记录,建立多对多的关系
INSERT INTO tb_user_mtm_course (uid, cid, created_time) VALUES (%s, %s, %s) [generated in 0.00007s]
[
(2, 3, datetime.datetime(2023, 9, 17, 14, 58, 41, 847895)),
(2, 4, datetime.datetime(2023, 9, 17, 14, 58, 41, 847895))
]
"""
# user_obj = User(
# name=fk.name(),
# course_list=[Course(name=f'张开带你玩转{fk.province()}') for i in range(2)]
# )
# session.add(user_obj)
# session.commit()
"""
多对多添加记录
模拟:用户记录已经存在了,为这个用户添加购买课程记录
"""
# # 先把用户创建出来
# user_obj = User(name=fk.name())
# session.add(user_obj)
# session.commit()
#
# # 再把用户记录过滤出来,为它添加课程记录
# user_obj = session.query(User).filter(User.name == user_obj.name).first()
# user_obj.course_list.append(Course(name=f'张开带你玩转{fk.province()}')) # 要添加的课程记录也可以是新创建的课程记录
# user_obj.course_list.append(session.get(Course, 1)) # 也可以是原有的课程记录
# session.commit()多对多查询记录
init_app.py和models.py代码不变,操作在test.py中:
import faker # https://www.cnblogs.com/Neeo/articles/11316724.html
from init_app import session
from models import Course, User
fk = faker.Faker(locale='zh_CN')
"""
多对多查询记录
"""
# 查询用户记录
# user_obj = session.get(User, 2)
# print(user_obj.name) # 潘玉兰
# print(user_obj.course_list.all()) # [<张开带你玩转河北省-3-0.00>, <张开带你玩转云南省-4-0.00>]
# print(user_obj.get_dict1) # {'name': '潘玉兰', 'money': 0.0}
# print(user_obj.get_dict2) # {'name': '潘玉兰', 'course_list': [{'name': '张开带你玩转河北省', 'price': 0.0}, {'name': '张开带你玩转云南省', 'price': 0.0}]}
# 查询课程记录
# course_obj = session.get(Course, 3)
# print(course_obj.name) # 张开带你玩转河北省
# print(course_obj.user_list) # [<潘玉兰-2-0.00>]
# print(course_obj.get_dict1) # {'name': '张开带你玩转河北省', 'price': 0.0}
# print(course_obj.get_dict2) # {'name': '张开带你玩转河北省', 'price': 0.0, 'user': [{'name': '潘玉兰', 'money': 0.0}]}多对多更新记录
init_app.py和models.py代码不变,操作在test.py中:
import faker # https://www.cnblogs.com/Neeo/articles/11316724.html
from init_app import session
from models import Course, User
fk = faker.Faker(locale='zh_CN')
"""
多对多更新记录
更新记录这里,通常是更新用户这边的所属的课程记录,比如新购买一门课程,或者退费某个课程,都需要调整多对多的绑定关系
而课程表,在用户表记录调整时,课程表的记录不会删除
"""
# user_obj = session.get(User, 2)
# # 现在这个用户购买了ID为3,4的两门课程
# # course_list = user_obj.course_list.all() # [<张开带你玩转河北省-3-0.00>, <张开带你玩转云南省-4-0.00>]
# # 根据需要删除他购买的课程对象
# # user_obj.course_list.remove(course_list[0])
# # session.commit()
"""
多对多更新记录
用户新购买了一门课程
"""
# user_obj = session.get(User, 2)
# course_obj = session.get(Course, 5)
# user_obj.course_list.append(course_obj)
# session.commit()
"""
多对多更新记录
用户新购买了多门课程
"""
# user_obj = session.get(User, 2)
# course_obj_list = session.query(Course).filter(Course.id.in_([2, 3])).all()
# user_obj.course_list.extend(course_obj_list)
# session.commit()
"""
多对多更新记录
调整用户所有跟课程有关的第三张表中的记录,也就是说把用户之前所有的课程购买记录都删掉,再重新绑定课程
"""
# 先把该用户现有的课程记录都清空
# user_obj = session.get(User, 2)
# course_obj_list = user_obj.course_list.all() # 前提这个用户必须有课程
# for course in course_obj_list: # 循环删除
# user_obj.course_list.remove(course)
# session.commit()
# 再给他重新绑定新的一个或者多个课程记录
# user_obj = session.get(User, 2)
# course_obj_list = session.query(Course).filter(Course.id.in_([2, 3])).all()
# user_obj.course_list.extend(course_obj_list)
# session.commit()多对多删除记录
init_app.py和models.py代码不变,操作在test.py中:
import faker # https://www.cnblogs.com/Neeo/articles/11316724.html
from init_app import session
from models import Course, User
fk = faker.Faker(locale='zh_CN')
"""
多对多删除记录
"""
# 如果要删除的用户是有购买课程的,删除效果是这样的:删除user表记录,删除第三张表的关联记录,课程表不受影响
# session.delete(session.get(User, 1))
# session.commit()
# 如果要删除的用户没有购买记录,直接删除即可,其他表不受影响
# session.delete(session.get(User, 4))
# session.commit()
"""
多对多删除记录
模拟:删除课程
"""
# 如果要删除的课程有用户购买,删除效果是这样的:删除Course表记录,删除第三张表的关联记录,用户表不受影响
# session.delete(session.get(Course, 1))
# session.commit()
# 如果要删除的课程并没有用户购买,直接删除即可,其它表都不受影响
# session.delete(session.get(Course, 6))
# session.commit()基于第三张表(模型类)建立多对多关联关系
在sqlalchemy中,基于db.Table创建的关系表,如果需要在第三张表新增除了外键以外其他字段,如何操作其它字段的数据,没法搞。所以将来实现多对多的时候,除了上面db.Table方案以外,还可以把关系表声明成模型的方法,如果声明成模型,则原来课程和学生之间的多对多的关系,就会变成一对多了。
init_app.py代码不变,调整models.py代码:
多对多添加记录
test.py:
import faker # https://www.cnblogs.com/Neeo/articles/11316724.html
from init_app import session
from models import Course, User, UserMTMCourse
fk = faker.Faker(locale='zh_CN')
"""
基于第三张表(模型类)的多对多关联关系,添加记录
分别添加用户和课程记录,不涉及多对多关联关系
"""
# 添加用户和课程记录
# session.add(User(name=fk.name()))
# session.add(Course(name=f'张开带你玩转{fk.province()}'))
# session.commit()
"""
基于第三张表(模型类)的多对多关联关系,添加记录
添加一个用户,同时为该用户添加三个购买课程记录
"""
# user_obj = User(
# name=fk.name(),
# # course_list是第三张表中的user_字段中backref的值
# course_list=[
# # 这里添加的是第三张表的记录对象
# UserMTMCourse(
# # 必须传入Course模型类对象,course_是UserMTMCourse中的course_字段名
# # course_的值才是真正的课程记录对象,这里可以新创建一个课程对象,也可以是查出来的已有的课程对象
# course_=Course(name=f'张开带你玩转{fk.province()}')
# )
# for i in range(3)
# ]
# )
# session.add(user_obj)
# session.commit()
"""
多对多添加记录
模拟:用户记录已经存在了,为这个用户添加购买课程记录
"""
# # 先把用户创建出来
# user_obj = User(name=fk.name())
# session.add(user_obj)
# session.commit()
#
# # 再把用户记录过滤出来,为它添加课程记录
# user_obj = session.query(User).filter(User.name == "刘婷").first()
# # user_obj.course_list.append(UserMTMCourse(course_=Course(name=f'张开带你玩转{fk.province()}'))) # 要添加的课程记录也可以是新创建的课程记录
# # user_obj.course_list.append(UserMTMCourse(course_=session.get(Course, 1))) # 也可以是原有的课程记录
# user_obj.course_list.extend([ # 也可以用extend添加多个
# UserMTMCourse(course_=session.get(Course, 2)),
# UserMTMCourse(course_=session.get(Course, 3))
# ])
# session.commit()
"""
上面代码user_obj.course_list.extend时,直接commit之后,SQL执行成功,但会有个SAWarning
SAWarning: Object of type <UserMTMCourse> not in session, add operation along 'Course.user_list' will not proceed
(This warning originated from the Session 'autoflush' process, which was invoked automatically
in response to a user-initiated operation.) UserMTMCourse(course_=session.get(Course, 3))
大致意思是说对象UserMTMCourse不在当前会话中,想要解决这个问题,需要在init_app.py,修改这行代码
Session = sessionmaker(bind=engine, autoflush=False) # 新增参数autoflush=False,表示在commit之前关闭自动flush。
这是一种临时解决的方式
"""
# 最好的方式,就是尽量不用user_obj.course_list.extend,而改为循环进行user_obj.course_list.append添加
# user_obj = session.query(User).filter(User.name == "刘婷").first()
# course_list = session.query(Course).filter(Course.id.in_([2, 3])).all()
# for course in course_list:
# user_obj.course_list.append(UserMTMCourse(course_=course))
# session.commit()有个问题需要注意的是,按照我们现在的第三张表的设计,是有缺陷的,那就是可以重复插入相同的关联记录。
test.py执行这个代码:
import faker # https://www.cnblogs.com/Neeo/articles/11316724.html
from init_app import session
from models import Course, User, UserMTMCourse
user_obj = session.get(User, 1)
user_obj.course_list.append(UserMTMCourse(course_=session.get(Course, 1)))
user_obj.course_list.append(UserMTMCourse(course_=session.get(Course, 1)))
user_obj.course_list.append(UserMTMCourse(course_=session.get(Course, 1)))
session.commit()那么第三张表中会出现什么情况呢?
session.add(User(name=fk.name()))
session.add(Course(name=f'张开带你玩转{fk.province()}'))
user_obj = session.get(User, 1)
user_obj.course_list.append(UserMTMCourse(course_=session.get(Course, 1)))
user_obj.course_list.append(UserMTMCourse(course_=session.get(Course, 1)))
user_obj.course_list.append(UserMTMCourse(course_=session.get(Course, 1)))
session.commit()
print([{'cid': i.cid, "uid": i.uid, 'user': i.user_.name, 'course': i.course_.name} for i in user_obj.course_list.all()])
"""
[
{'cid': 1, 'uid': 1, 'user': '孙秀荣', 'course': '张开带你玩转广西壮族自治区'},
{'cid': 1, 'uid': 1, 'user': '孙秀荣', 'course': '张开带你玩转广西壮族自治区'},
{'cid': 1, 'uid': 1, 'user': '孙秀荣', 'course': '张开带你玩转广西壮族自治区'}
]
通过打印结果可以看到,第三张表中,相同的关联关系,建立了三次,而真实情况,只需要一次就行了
"""对于这种情况,你可以选择对查询结果进行去重,当然更好的方案是选择为第三张表创建一个用户和课程的联合索引。
models.py:
from datetime import datetime
# sqlalchemy包导入好了常见的字段类型,我们这里直接导入即可,我为了少敲几个字,通过as语句起个简单的别名
import sqlalchemy as db
from sqlalchemy.dialects import mysql
from sqlalchemy.orm import relationship, declarative_base, backref
from init_app import engine
Model = declarative_base()
class UserMTMCourse(Model):
""" 第三张表,绑定User表和Course表的多对多关系,且该表会在数据库中真实的被创建出来 """
__tablename__ = "tb_user_mtm_course"
id = db.Column(db.Integer, primary_key=True, autoincrement=True, comment='主键ID')
uid = db.Column(db.Integer, db.ForeignKey("tb_user.id"), comment="用户ID")
cid = db.Column(db.Integer, db.ForeignKey("tb_course.id"), comment="课程ID")
created_time = db.Column(db.DateTime, default=datetime.now, comment="购买时间")
user_ = relationship('User', uselist=False, backref=backref('course_list', uselist=True, lazy='dynamic'))
course_ = relationship('Course', uselist=False, backref=backref('user_list', uselist=True, lazy='dynamic'))
db.UniqueConstraint('uid', 'cid', name='uc_id')
__table_args__ = ( # 注意,这是个元组,如果只有一个元素,元素后面要带逗号哦
# 操蛋的是,pycharm中通过database提供的ddl建表语句中,找不到这个联合索引的SQL语句,搞得我以为这个姿势不对
# 后来,我自己去数据库执行show create table tb_user_mtm_course;才找到联合索引,UNIQUE KEY `uc_id` (`uid`,`cid`),
db.UniqueConstraint('uid', 'cid', name='uc_id'), # 联合索引
)当你在插入重复记录的时候,就会报错了,我们可以捕获这个错误,从而避免掉重复添加记录的情况。
test.py:
自关联
原生SQL语句
常见报错
sqlalchemy.exc.OperationalError: (MySQLdb.OperationalError) (1049, "Unknown database 'alchemy'")
这个报错是因为你sqlalchemy要连接的mysql数据库中,没有提前把对应的alchemy数据库创建好,那么解决办法也就有了,手动提前把alchemy创建好即可。
create database alchemy charset=utf8mb4;