 王张开
王张开[TOC]
about
scrapy是爬虫中封装好的一个明星框架。
主要功能:高性能的持久化存储、异步的数据下载、高性能的数据分析、以及分布式的数据爬取等等.....
install
mac或linux平台直接下载即可:
# mac/linux
pip install scrapyWindows平台就稍微麻烦些:
# 首先下载wheel模块,用于后续安装twisted模块
pip install wheel
# 下载Twisted
pip install Twisted
# 下载pywin32
pip install pywin32
# 下载scrapy
pip install scrapy
# 下载成功后,可以终端输入如下命令测试
scrapy version
D:\Downloads>scrapy version
Scrapy 2.5.1快速上手
scrapy框架的使用,跟Django差不多,也是使用命令创建一个项目(或称之为工程),然后继续使用命令创建相关文件、然后继续使用命令执行scrapy框架......
接下来我们通过一个示例来演示这一过程。注意,我的终端所在路径。
1. 创建一个scrapy项目
在终端中操作:
# 命令:
scrapy startproject project_name
D:\tmp>scrapy startproject firstBlood
New Scrapy project 'firstBlood', using template directory 'c:\programdata\anaconda3\lib\site-packages\scrapy
\templates\project', created in:
D:\tmp\firstBlood
You can start your first spider with:
cd firstBlood
scrapy genspider example example.com2. cd到项目目录下,创建爬虫文件
# 命令
cd firstBlood
scrapy genspider 爬虫文件名 域名 # 域名可以瞎写一个,比如www.xxx.com,后面可以手动修改
D:\tmp>cd firstBlood
D:\tmp\firstBlood>scrapy genspider first_demo www.baidu.com
Created spider 'first_demo' using template 'basic' in module:
firstBlood.spiders.first_demo现在,firstBlood项目的目录结构是这样的:
D:\tmp\firstBlood # 爬虫工程目录
├─scrapy.cfg # scrapy配置信息,但真正爬虫相关的配置都在settings.py文件中
│
└─firstBlood # 项目目录,目前只关注一个settings文件即可
├─ items.py # 设置数据存储模板,用于结构化数据
├─ middlewares.py # 中间件,可以配置关于请求头的修改、ip代理池等
├─ pipelines.py # 数据的持久化处理
├─ settings.py # 爬虫配置文件,如递归层数、并发数、延迟下载等
├─ __init__.py
│
└─spiders # 爬虫文件目录,主要编写爬虫主要逻辑
├─ first_demo.py # 之前通过命令创建的爬虫文件,我们的爬虫代码都编写到这个文件中
└─ __init__.py3. 编写爬虫文件和配置文件,然我们的爬虫项目跑起来
first_demo.py:
当这个文件被创建后,scrapy就帮我们创建好了一个爬虫模板,我们只需根据自己的情况,稍作修改就可以了。
import scrapy
class FirstDemoSpider(scrapy.Spider):
# name:frist_demo文件在当前项目中的唯一标识
name = 'first_demo'
# allowed_domains:允许start_urls中哪些url可以被访问,一般,我们都注释掉这个属性
# allowed_domains = ['www.baidu.com']
# 当执行项目时,这个列表中的url将被一一执行,我们手动的添加一个链接
start_urls = ['https://www.baidu.com/', 'https://www.cnblogs.com']
def parse(self, response):
""" 请求结果的数据解析在这个方法中解析 """
# 11111111 这是个人习惯,为了很快的在console中定位到这行打印的输出位置
print(11111111, response)4. 让我们的爬虫项目跑起来
此时,你可以无脑的执行下面的代码,来看项目的执行结果:
# 命令
scrapy crawl 爬虫文件
D:\tmp\firstBlood>scrapy crawl first_demo
2021-12-16 16:29:16 [scrapy.utils.log] INFO: Scrapy 2.5.1 started (bot: firstBlood)
2021-12-16 16:29:16 [scrapy.utils.log] INFO: Versions: lxml 4.6.3.0, libxml2 2.9.10, cssselect 1.1.0, parsel
1.6.0, w3lib 1.22.0, Twisted 20.3.0, Python 3.8.8 (default, Apr 13 2021, 15:08:03) [MSC v.1916 64 bit (AMD6
4)], pyOpenSSL 20.0.1 (OpenSSL 1.1.1k 25 Mar 2021), cryptography 3.4.7, Platform Windows-10-10.0.19041-SP0
2021-12-16 16:29:16 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.selectreactor.SelectReactor
2021-12-16 16:29:16 [scrapy.crawler] INFO: Overridden settings:
{'BOT_NAME': 'firstBlood',
'NEWSPIDER_MODULE': 'firstBlood.spiders',
'ROBOTSTXT_OBEY': True,
'SPIDER_MODULES': ['firstBlood.spiders']}
2021-12-16 16:29:16 [scrapy.extensions.telnet] INFO: Telnet Password: ad3996f06af9c89c
2021-12-16 16:29:16 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2021-12-16 16:29:16 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2021-12-16 16:29:16 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2021-12-16 16:29:16 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2021-12-16 16:29:16 [scrapy.core.engine] INFO: Spider opened
2021-12-16 16:29:16 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at
0 items/min)
2021-12-16 16:29:16 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2021-12-16 16:29:16 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.baidu.com/robots.txt> (refere
r: None)
2021-12-16 16:29:16 [scrapy.downloadermiddlewares.robotstxt] DEBUG: Forbidden by robots.txt: <GET https://ww
w.baidu.com/>
2021-12-16 16:29:21 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.cnblogs.com/robots.txt> (refe
rer: None)
2021-12-16 16:29:21 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.cnblogs.com> (referer: None)
11111111 <200 https://www.cnblogs.com>
2021-12-16 16:29:22 [scrapy.core.engine] INFO: Closing spider (finished)
2021-12-16 16:29:22 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/exception_count': 1,
'downloader/exception_type_count/scrapy.exceptions.IgnoreRequest': 1,
'downloader/request_bytes': 675,
'downloader/request_count': 3,
'downloader/request_method_count/GET': 3,
'downloader/response_bytes': 16328,
'downloader/response_count': 3,
'downloader/response_status_count/200': 3,
'elapsed_time_seconds': 5.369018,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2021, 12, 16, 8, 29, 22, 56525),
'httpcompression/response_bytes': 78548,
'httpcompression/response_count': 2,
'log_count/DEBUG': 4,
'log_count/INFO': 10,
'response_received_count': 3,
'robotstxt/forbidden': 1,
'robotstxt/request_count': 2,
'robotstxt/response_count': 2,
'robotstxt/response_status_count/200': 2,
'scheduler/dequeued': 2,
'scheduler/dequeued/memory': 2,
'scheduler/enqueued': 2,
'scheduler/enqueued/memory': 2,
'start_time': datetime.datetime(2021, 12, 16, 8, 29, 16, 687507)}
2021-12-16 16:29:22 [scrapy.core.engine] INFO: Spider closed (finished)如上输出结果中,我们的两行print结果,已经被茫茫的日志信息淹没了........
那有个简单的解决办法,让其运行时,只输出我们的print信息,而不要其他日志信息:
# 命令
scrapy crawl first --nolog # 不建议用, 因为如果有报错,也不输出了
D:\tmp\firstBlood>scrapy crawl first_demo --nolog
11111111 <200 https://www.cnblogs.com>除了不建议用这个--nolog外,貌似还有点问题,我们的first_demo.py中的start_urls列表中有两个url,但上述结果怎么就一个????另一个呢?
稳住,这个时候,我们需要调整一下settings.py文件了,下面只粘贴修改的部分代码了:
# Obey robots.txt rules
# ROBOTSTXT_OBEY = True # 默认的遵循爬虫规则,我们这里改为False
ROBOTSTXT_OBEY = False
# 新添加一个参数
# 解决--nolog参数的弊端,这里我们自定义日志输出级别,当程序出错时,输出报错信息
LOG_LEVEL = "ERROR"这个时候,我们再运行项目,基本上想要的输出就都有了:
D:\tmp\firstBlood>scrapy crawl first_demo
11111111 <200 https://www.baidu.com/>
11111111 <200 https://www.cnblogs.com>ok,scrapy框架的基本使用,就这些了。
PyCharm配置scrapy运行环境
win10 + python3.9 + scrapy2.5.1 + pycharm2020.1.1
习惯了pycharm的右键运行,这scrapy的爬虫项目运行在终端中执行命令,就感觉非常麻烦,这里呢,讲讲怎么配置PyCharm配置scrapy运行环境。
示例还是上一个小节的firstBlood项目。
在项目目录的同级目录,也就是跟scrapy.cfg文件同级,创建一个main.py文件,当然你也可以叫别的名字。
import os
import sys
from scrapy import cmdline
sys.path.insert(0, os.path.dirname(os.path.abspath(__file__)))
cmdline.execute(['scrapy', "crawl", "first_demo"]) # first_demo 是你的爬虫文件然后按下图操作:
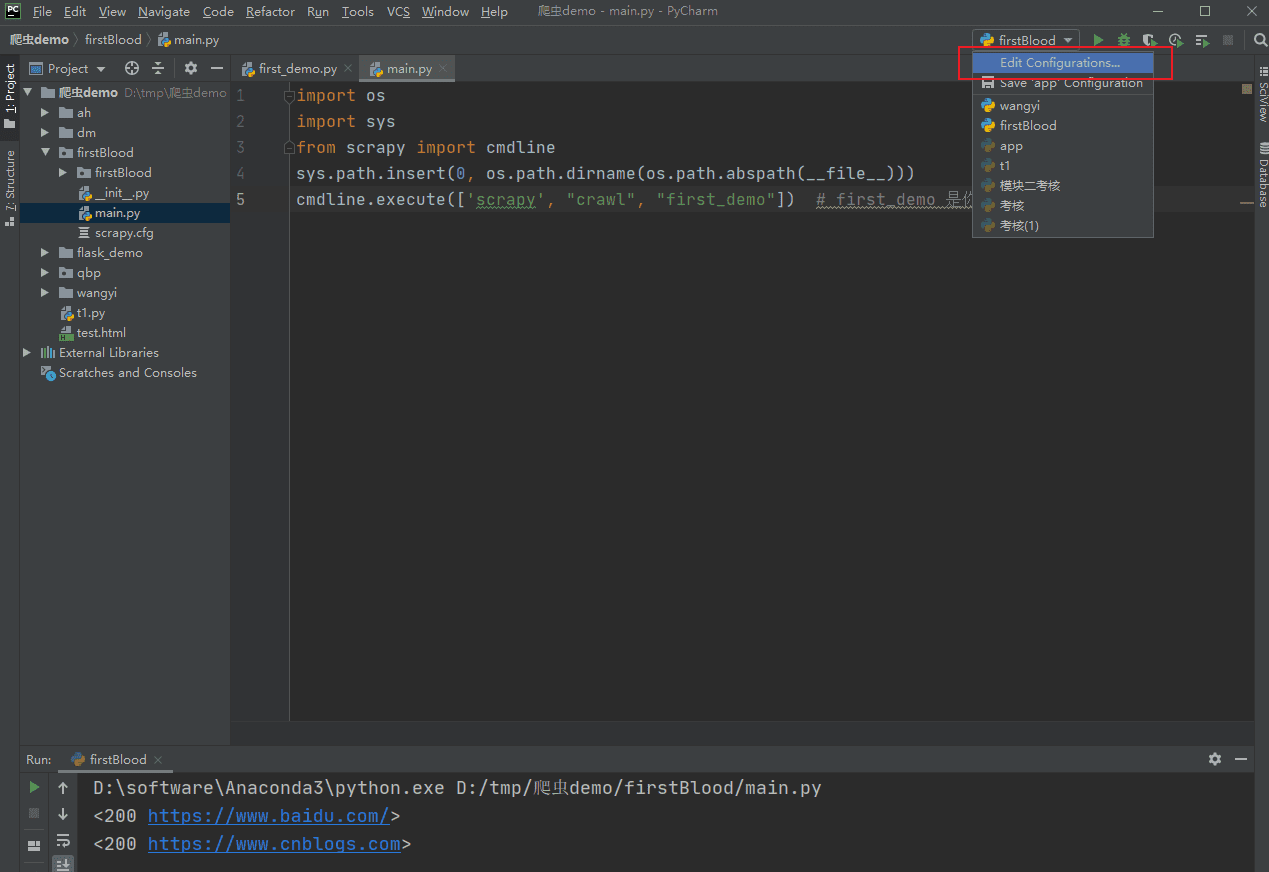
然后配置:

完了之后,就可以点击运行按钮运行了:
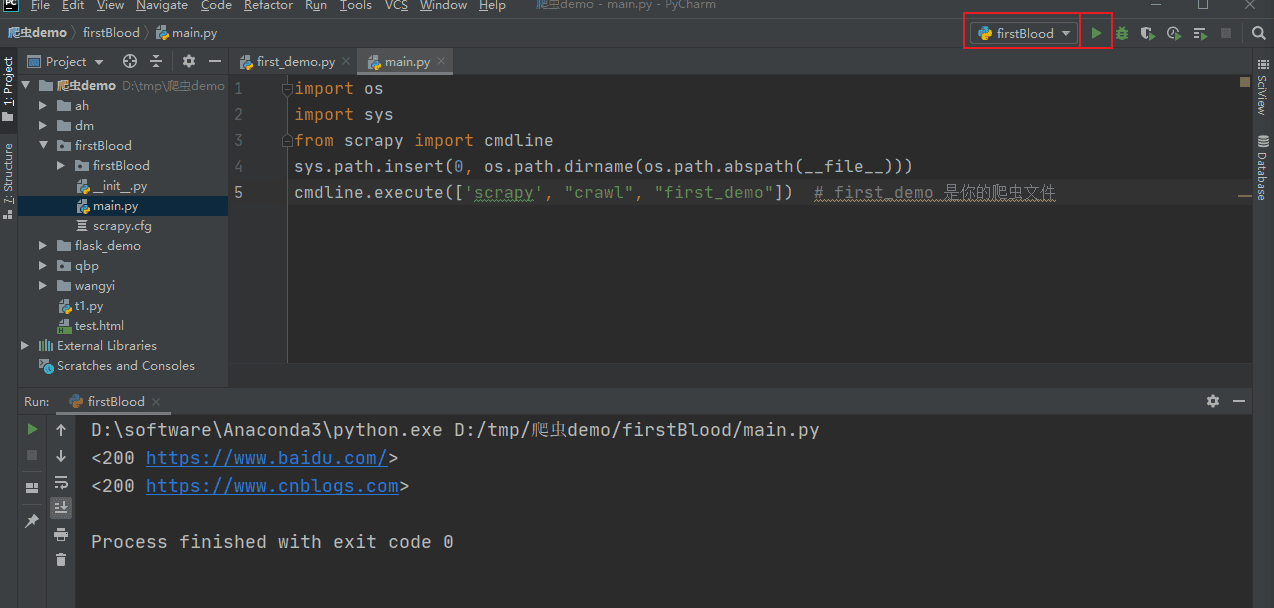
数据解析
接下来根据一个实战,来学习如何解析请求到的数据。
示例是爬取糗事百科。
scrapy startproject qbp
cd qbp
scrapy genspider qb www.xxx.com爬虫文件qb.py:
import scrapy
class QbSpider(scrapy.Spider):
name = 'qb'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.qiushibaike.com/text/']
def parse(self, response):
# 存储所有拿到的数据
data_list = []
# div_list = response.xpath('//*[@id="content"]/div/div[2]')
div_list = response.xpath('//*[@id="content"]/div/div[2]/div')
for div in div_list:
"""
xpath返回的是列表,列表中的元素是Selector类型的对象
如果对Selector对象使用extract方法,extract方法可以将Selector类型的对象的data值提取出来
如果对列表使用extract方法,extract方法会将列表中每一个Selector对象中的data值提取出来
extract_first方法提取列表中第一个Selector对象的data值提取出来
"""
# author = div.xpath("./div[1]/a[2]/h2/text()")[0].extract()
# 作者的结果列表中只有一个Selector对象,所以可以使用extract_first方法
author = div.xpath("./div[1]/a[2]/h2/text()").extract_first()
content = div.xpath("./a/div/span[1]//text()").extract()
print(author.strip())
print(''.join(content).strip())
content = ''.join(content).strip()
data_list.append({
"author": author.strip(),
"content": content
})
return data_list
# 代码截止到2021/12/20号运行无误settings.py中修改的部分代码:
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36'
LOG_LEVEL = "ERROR"
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# 如果代码运行报错:AttributeError: 'TelnetConsole' object has no attribute 'port'
# 就设置下面的参数
TELNETCONSOLE_PORT = None数据的持久化
当我们解析到了数据,就要考虑怎么保存数据了,也就是如何进行数据持久化。
在scrapy中,数据的持久化:
- 基于终端指令的数据持久化。
- 限制:只可以将parse方法的返回值存储到本地的文件中。
- 基于管道进行持久化。
基于终端指令的数据持久化
来看怎么操作,示例还是用上一小节的示例。
代码不变,在终端执行scrapy项目,然后跟持久化的相关命令:
scrapy crawl qb -o data.csv
# 不想要输出日志信息,还可以加 --nolog
scrapy crawl qb -o data.csv --nolog-o输出的文件类型可以有'json', 'jsonlines', 'jl', 'csv', 'xml', 'marshal', 'pickle'这些。
基于管道的数据持久化
本小节的实例还是基于上面糗事百科的示例,然后稍作修改。
基于管道的数据持久化的编码流程
- 数据解析
- 即在爬虫文件中进行请求结果的处理
qb.py:
import scrapy
from qbp.items import QbpItem
class QbSpider(scrapy.Spider):
name = 'qb'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.qiushibaike.com/text/']
def parse(self, response):
# 存储所有拿到的数据
data_list = []
div_list = response.xpath('//*[@id="content"]/div/div[2]/div')
for div in div_list:
author = div.xpath("./div[1]/a[2]/h2/text()").extract_first()
content = div.xpath("./a/div/span[1]//text()").extract()
content = ''.join(content).strip()
# 将解析到的数据封装成item对象
item = QbpItem()
# 这两个key要跟QbpItem类中定义的两个属性对应
item['author'] = author.strip()
item['content'] = content
# 将封装好的item对象提交给管道
yield item- 将解析的数据封装存储到item类型的对象中,并将item类型的对象提交给管道进行持久化存储的操作
- 操作的是
items.py文件
- 操作的是
items.py:
import scrapy
class QbpItem(scrapy.Item):
# 爬虫文件中,解析到的请求结果就两个字段,所以这里对应的定义两个属性,算是固定的写法吧
author = scrapy.Field()
content = scrapy.Field()- 在管道类的process_item方法中要将其接收的item类型的对象中存储的数据进行持久化操作
- 操作的是
piplines.py文件
- 操作的是
pipelines.py:
class QbpPipeline:
"""
一个管道类对应将一组数据存储到一个平台或者载体中,
如果要分别存储到多个载体中,请再写对应的管道类,然后在settings中注册
"""
def open_spider(self, spider):
"""
重写父类的open_spider方法
该方法只在爬虫程序开始运行时调用一次
我们重写该方法的原因是想在这个方法被调用时,拿到一个文件对象,
用于process_item方法中保存数据结果
又因为process_item方法可能会执行多次,所以文件对象要是写在process_item方法中
就会多次打开,不太好,所以在open_spider方法中打开一次,就好了
:param spider:
:return:
"""
print('爬虫程序开始执行.....')
self.f = open('./qb.txt', 'w', encoding='utf8')
def process_item(self, item, spider):
"""
该方法专门用来处理item类型对象的
且,该方法每接收到一个item对象就会被调用一次
:param item:
:param spider:
:return:
"""
# 先将数据从item中提取出来
author = item['author']
content = item['content']
# 写入到文件
self.f.write(f'{author}:{content}\n')
# 通过return语句,将item对象传递给下一个即将被执行的管道类
# 虽然我们这个示例中只有一个管道类,但强烈建议也写上,避免出现不必要的问题
return item
def close_spider(self, spider):
"""
重写父类的close_spider方法,该方法与open_spider方法对应,在爬虫程序结束时执行一次
我们正好在这里可以关闭文件
:param spider:
:return:
"""
print('爬虫程序执行完毕。')
self.f.close()- 在配置文件中开启管道
- 操作的是
settings.py文件
- 操作的是
settings.py:
BOT_NAME = 'qbp'
SPIDER_MODULES = ['qbp.spiders']
NEWSPIDER_MODULE = 'qbp.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36'
LOG_LEVEL = "ERROR"
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# 如果代码运行报错:AttributeError: 'TelnetConsole' object has no attribute 'port'
# 就设置下面的参数
TELNETCONSOLE_PORT = None
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
# 300表示优先级,数值越小优先级越高
# 因为可以多个管道类,所以可以设置优先级的方式来决定使用哪个管道类
'qbp.pipelines.QbpPipeline': 300,
}基于管道的数据持久化的特点
- 优点:通用性强。在管道类中,随你决定将解析到的数据存哪!数据库?文件?都随你。
- 缺点,写起来稍微优点麻烦。
基于管道的数据持久化进阶
本小节,主要就是说说如何将解析到的数据,分别保存,即有这样的一道面试题,我们应该如何处理。
面试题:将scrapy爬取到的数据一份存储到本地文本文件,一份存储到MySQL,如何实现?
这个面试题的解决方案,其实也不难,数据解析、封装item这部分代码不变,只需要修改管道相关的代码即可,也就是写多个管道类来实现。
qb.py代码不变:
import scrapy
from qbp.items import QbpItem
class QbSpider(scrapy.Spider):
name = 'qb'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.qiushibaike.com/text/']
def parse(self, response):
# 存储所有拿到的数据
data_list = []
div_list = response.xpath('//*[@id="content"]/div/div[2]/div')
for div in div_list:
author = div.xpath("./div[1]/a[2]/h2/text()").extract_first()
content = div.xpath("./a/div/span[1]//text()").extract()
content = ''.join(content).strip()
# 将解析到的数据封装成item对象
item = QbpItem()
# 这两个key要跟QbpItem类中定义的两个属性对应
item['author'] = author.strip()
item['content'] = content
# 将封装好的item对象提交给管道
yield itemitems.py代码不变:
import scrapy
class QbpItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
author = scrapy.Field()
content = scrapy.Field()主要修改的就是管道文件pipelines.py:
import pymysql
from pymysql.connections import CLIENT
"""
一个管道类对应将一组数据存储到一个平台或者载体中,
如果要分别存储到多个载体中,请再写对应的管道类,然后在settings中注册
"""
class QbpPipeline:
def open_spider(self, spider):
self.f = open('./qb.txt', 'w', encoding='utf8')
def process_item(self, item, spider):
# 先将数据从item中提取出来
author = item['author']
content = item['content']
# 写入到文件
self.f.write(f'{author}:{content}\n')
# 通过return语句,将item对象传递给下一个即将被执行的管道类
# 虽然我们这个示例中只有一个,但强烈建议也写上,避免出现不必要的问题
return item
def close_spider(self, spider):
self.f.close()
class MySQLPipeline(object):
def open_spider(self, spider):
""" 创建数据库链接对象,并且准备好表 """
self.conn = pymysql.Connect(
host='127.0.0.1', user='root', password='123',
database='', charset='utf8', client_flag=CLIENT.MULTI_STATEMENTS
)
self.cursor = self.conn.cursor()
# 下面这个sql是我懒的去数据库创建了,也直接写好了
sql = """
DROP DATABASE IF EXISTS {databaseName};
CREATE DATABASE {databaseName} CHARSET utf8;
USE {databaseName};
DROP TABLE IF EXISTS {tableName};
CREATE TABLE {tableName}(
author varchar(64),
content varchar(8192)
) ENGINE=INNODB CHARSET=utf8;""".format(databaseName="qbdb", tableName="qb")
self.cursor.execute(sql)
self.conn.commit()
def close_spider(self, spider):
""" 关闭数据库链接和游标 """
# 这个查询可以删除,我懒得去数据库查看,就在这打印了
self.cursor.execute('select * from qb;')
# print(self.cursor.fetchall())
for a, c in self.cursor.fetchall():
print(a, c)
self.conn.commit()
self.cursor.close()
self.conn.close()
def process_item(self, item, spider):
try:
self.cursor.execute("insert into qb values(%s, %s);", (item['author'], item['content']))
self.conn.commit()
except Exception as e:
print(e)
self.conn.rollback()
# 养成好习惯,加上return
return item然后将新添加的管道类注册到settings.py中:
BOT_NAME = 'qbp'
SPIDER_MODULES = ['qbp.spiders']
NEWSPIDER_MODULE = 'qbp.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36'
LOG_LEVEL = "ERROR"
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# 如果代码运行报错:AttributeError: 'TelnetConsole' object has no attribute 'port'
# 就设置下面的参数
TELNETCONSOLE_PORT = None
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
# 300表示优先级,数值越小优先级越高
# 因为可以多个管道类,所以可以设置优先级的方式来决定使用哪个管道类
'qbp.pipelines.QbpPipeline': 300,
'qbp.pipelines.MySQLPipeline': 301,
}本小节的重点就是:
- 一个管道类负责处理一种持久化方案。
- 爬虫文件提交的item只会给第一个管道类,后续管道类都依赖于第一个管道类中process_item方法的返回值,即
return item,通过这个返回值将item在多个管道类中传递。
全站数据爬取
所谓基于scrapy的全站数据爬取,就是将某网站中某板块下的全部页码对应的页面数据进行爬取。
本小节的示例就是爬取汽车之间新闻页那好几千页的新闻。
实现全站爬取的方式:
- 将所有页面的url添加到
start_urls列表中,但这不现实,页面少了还行, 但我们这有几千页....所以不推荐。 - 推荐自行手动进行url的拼接,然后让其自动请求拼接好的url,实现循环的请求所有页面。
来看操作,首先创建项目:
scrapy startproject ah
cd ah
scrapy genspider car www.xxx.comcar.py:
import scrapy
class CarSpider(scrapy.Spider):
name = 'car'
# allowed_domains = ['www.xxx.com']
# 首页就这样了
start_urls = ['https://www.autohome.com.cn/all/']
# 后续页面url的模板
next_url_template = "https://www.autohome.com.cn/all/{}/#liststart"
# 从第几页开始到第几页结束,这里从第二页开始到第十页结束,所有页码需要手动处理,第一页就在start_urls中就那样了
start_page_num = 2
end_page_num = 10
def parse(self, response):
li_list = response.xpath('//*[@id="auto-channel-lazyload-article"]/*/li')
print("请求的页面的url: ", response.url)
for li in li_list:
title = li.xpath("./a/h3/text() | ./a/p/text()").extract_first()
if not title: # 有些li是空的,所以取出来是None
continue
print(title)
break # 一页内容太多,这里只每页打印一条
# 结束爬取的条件
if self.start_page_num <= self.end_page_num:
# 上面那个url模板不能动,所以要根据模板和页码生成下一个可用的url
tmp_url = self.next_url_template.format(self.start_page_num)
# 下面yield是固定写法,
# yield scrapy.Request(url=要爬取下一页的url, callback=爬取到的数据让谁解析)
yield scrapy.Request(url=tmp_url, callback=self.parse)
# 页码加一没啥好说的
self.start_page_num += 1
# 代码截至到2021/12/29号运行无误settings.py也简单的修改下:
BOT_NAME = 'ah'
SPIDER_MODULES = ['ah.spiders']
NEWSPIDER_MODULE = 'ah.spiders'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36'
LOG_LEVEL = "ERROR"
# Obey robots.txt rules
# ROBOTSTXT_OBEY = True
ROBOTSTXT_OBEY = False爬取效果如下:
D:\ah>scrapy crawl car
请求的页面的url: https://www.autohome.com.cn/all/
风神AX7 PRO将OTA WindLink6.0车机系统
请求的页面的url: https://www.autohome.com.cn/all/2/
【快讯|2022款斯巴鲁傲虎售31.28万元起】日前,我们从斯巴鲁官网获悉,2022款傲虎正式上市,新车推出3款车型可选,售
价区间为31.28万-33...
请求的页面的url: https://www.autohome.com.cn/all/3/
【快讯|受疫情影响,坦克300暂停西安地区发车】近日,根据坦克官方公布的发车消息来看,12月累计发车9373台,累计到店
78798台,发运在途5527...
请求的页面的url: https://www.autohome.com.cn/all/4/
9.98万元起售 哈弗赤兔多款新车型上市
请求的页面的url: https://www.autohome.com.cn/all/5/
比亚迪与Momenta成立公司 “迪派智行”
请求的页面的url: https://www.autohome.com.cn/all/6/
神州租车正式开启2022年春节租车预订
请求的页面的url: https://www.autohome.com.cn/all/7/
JR-改装社:长安UNI-T 李宁设计限量版
请求的页面的url: https://www.autohome.com.cn/all/8/
冬季/高速续航如何?威马W6长测第七期
请求的页面的url: https://www.autohome.com.cn/all/9/
小马智行与一汽(南京)达成战略合作
请求的页面的url: https://www.autohome.com.cn/all/10/
【快讯|2022款零跑T03将于12月28日上市】日前,我们从官方获悉,2022款零跑T03将于12月28日上市,预计新车将会延用现
款车型的外观和内饰...How Scrapy Works
我们通过几个示例也大致的对scrapy有了了解。
那scrapy是如何工作的呢?本小节就来梳理一下scrapy的工作流程。
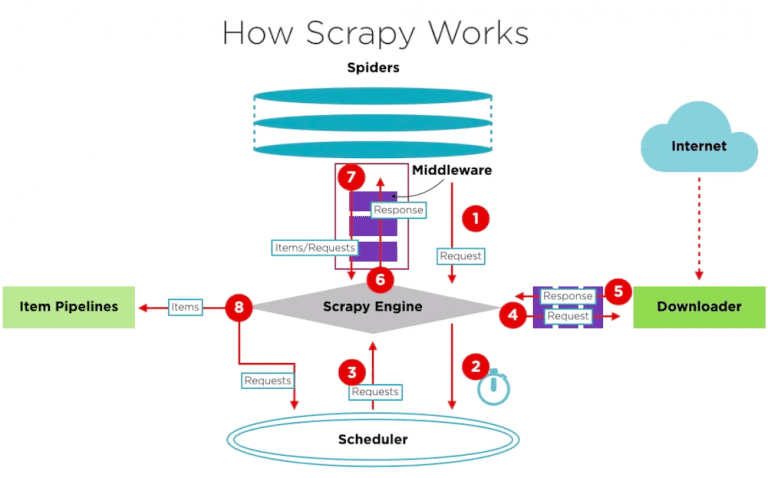
图片摘自:Scrapy新手上路
- 引擎(scrapy engine):用来处理整个系统的数据流处理,并出发事务(框架的核心)。
- 调度器(scheduler):用来接收引擎发过来的请求,将请求压入队列,并在引擎再次请求时返回。可以想象成一个url的优先队列,由它来决定下一个要抓取的url是什么,同时去除重复的url。
- 下载器(downloader):用于访问url并获取结果,返回给引擎。
- 下载器是建立在twisted这个高效的异步模型上的。
- 爬虫(spiders):爬虫文件是主要干活的,用于从url中提取自己需要的数据,即所谓的实体(item),用户也可以在此提取出链接,让scrapy继续爬取下一个url。
- 管道(pipelines):负责处理爬虫文件从请求结果中提取的item,其主要作用就是持久化,并可以在持久化时,进行数据清晰、有效性验证。
item对象的传递
这一小节中,所谓的请求传参并不是你想象的那个在请求的url上或者请求体中携带参数,用于发请求。而是描述这样的一个场景:
- 请求A的列表页,然后解析出来数据封装到item对象中,然后又要从解析出的url中访问详情页,再获取详情页的数据并封装到item中。
- 问题来了,不同的页面解析方式也是不同的,通常多个页面我们用多个解析方法完成数据解析操作,那么在多个解析方法中如何传递同一个item对象?然后提交给管道进行持久化。这就是本小节的内容。
示例还是汽车之家的示例。需求就是找到新闻对应的详情页,然后从详情页中获取点数据就可以了。
items.py非常简单:
import scrapy
class AhItem(scrapy.Item):
title = scrapy.Field()
detail_title = scrapy.Field()重点还是在爬虫文件中car.py:
import scrapy
from ah.items import AhItem
class CarSpider(scrapy.Spider):
name = 'car'
# allowed_domains = ['www.xxx.com']
# 首页就这样了
start_urls = ['https://www.autohome.com.cn/all/']
# 后续页面url的模板
next_url_template = "https://www.autohome.com.cn/all/{}/#liststart"
# 从第几页开始到第几页结束,这里从第二页开始到第十页结束,所有页码需要手动处理,第一页就在start_urls中就那样了
start_page_num = 2
end_page_num = 4
def detail_parse(self, response):
# 通过response.meta['item_obj']接收来自上一个解析方法的item对象
item_obj = response.meta['item_obj']
detail_title = response.xpath("/html/head/title/text()").extract_first()
item_obj['detail_title'] = detail_title
# 别忘了yield
yield item_obj
def parse(self, response):
li_list = response.xpath('//*[@id="auto-channel-lazyload-article"]/*/li')
for li in li_list:
title = li.xpath("./a/h3/text() | ./a/p/text()").extract_first()
if not title:
continue
detail_url = "https:" + li.xpath("./a/@href").extract_first()
item_obj = AhItem()
item_obj['title'] = title
# 想要在下一个解析方法中使用同一个item对象,就通过meta以字典的形式传递
yield scrapy.Request(url=detail_url, callback=self.detail_parse, meta={"item_obj": item_obj})
# 结束爬取的条件
if self.start_page_num <= self.end_page_num:
# 上面那个url模板不能动,所以要根据模板和页码生成下一个可用的url
tmp_url = self.next_url_template.format(self.start_page_num)
# 下面yield是固定写法,
# yield scrapy.Request(url=要爬取下一页的url, callback=爬取到的数据让谁解析)
yield scrapy.Request(url=tmp_url, callback=self.parse)
# 页码加一没啥好说的
self.start_page_num += 1这里的pipelines.py就不做持久化了,简单的打印下就得了。
class AhPipeline:
def process_item(self, item, spider):
print(11111, item)
return item最后,运行之前,别忘了修改settings.py文件:
BOT_NAME = 'ah'
SPIDER_MODULES = ['ah.spiders']
NEWSPIDER_MODULE = 'ah.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36'
LOG_LEVEL = "ERROR"
# Obey robots.txt rules
# ROBOTSTXT_OBEY = True
ROBOTSTXT_OBEY = False
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'ah.pipelines.AhPipeline': 300,
}ImagesPipeline
爬取图片我们可以自己解析到图片地址,然后发请求,再然后在管道中进行持久化的。但是scrapy也单独的封装了一个管道类,帮助我们实现图片的爬取,我们来看看怎么用的吧。
示例还是汽车之家,爬取新闻页的每条新闻的缩略图。
重点代码就是管道类和settings配置了。
首先items.py定义图片的src:
import scrapy
class AhItem(scrapy.Item):
src = scrapy.Field()然后car.py解析出图片地址,并封装到item对象中。
import scrapy
from ah.items import AhItem
class CarSpider(scrapy.Spider):
name = 'car'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.autohome.com.cn/all/']
def parse(self, response):
li_list = response.xpath('//*[@id="auto-channel-lazyload-article"]/*/li')
for li in li_list:
title = li.xpath("./a/h3/text() | ./a/p/text()").extract_first()
if not title:
continue
# 有的图片是完整的url,有的不是,所以要处理下
img_src = li.xpath("./a/div[1]/img/@src").extract_first()
if not img_src.startswith("https"):
img_src = "https:" + li.xpath("./a/div[1]/img/@src").extract_first()
item_obj = AhItem()
item_obj['src'] = img_src
yield item_obj重点就是pipelines.py文件了,要自定义一个图片的管道类,然后继承scrapy的提供的图片管道类。
然后自定义的管道类中重写3个父类的方法:
import scrapy
from scrapy.pipelines.images import ImagesPipeline
class AhPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
"""
重写父类的方法:根据图片地址发请求
"""
yield scrapy.Request(item['src'])
def file_path(self, request, response=None, info=None, *, item=None):
"""
重写父类的方法:处理图片名称;而路径我们在settings.py中指定
"""
# 图片名称我们就以图片url上的为准
# https://www2.autoimg.cn/newsdfs/g29/M0A/DE/5B/
# 120x90_0_autohomecar__Chxkm2HMBOqAIWBOAAEzJIr5p2o367.jpg
return request.url.rsplit("/", 1)[-1]
def item_completed(self, results, item, info):
"""
重写父类的方法:
将爬取的内容返回给下一个即将被执行的管道类,这里没有下一个管道类了
直接return item,scrapy就会自动的将图片内容写到指定的目录中
"""
return item别忘了settings.py:
BOT_NAME = 'ah'
SPIDER_MODULES = ['ah.spiders']
NEWSPIDER_MODULE = 'ah.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36'
LOG_LEVEL = "ERROR"
# Obey robots.txt rules
# ROBOTSTXT_OBEY = True
ROBOTSTXT_OBEY = False
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'ah.pipelines.AhPipeline': 300,
}
# 配置图片的保存目录,该目录如果不存在则自动创建
IMAGES_STORE = "./imgs"小结,使用流程梳理:
- 数据解析,解析出图片的地址并封装到item对象中。
- 将item对象提交到自定义管道。
- 自定义管道类继承ImagesPipeline,并重写3个方法:
- get_media_requests
- file_path
- item_completed
- 在配置文件中进行配置:
- 指定图片的存储目录:
IMAGES_STROE = 路径 - 指定开启管道ITEM_PIPELINES,自定义的管道类。
- 指定图片的存储目录:
下载中间件
下载中间件,它位于引擎和下载器之间,用于拦截请求和响应,进而对请求和响应做进一步的处理,比如添加UA伪装,设置代理池、对响应结果的进一步处理.....等等。
拦截请求:UA伪装和代理池
这里新建一个爬虫项目吧。
scrapy startproject dm
cd dm
scrapy genspider mw www.xxx.com首先我使用flask搞了个server端,可以用来看查看请求头。
随便新建一个app.py,然后运行即可。
from flask import Flask, jsonify, request
app = Flask(__name__)
@app.route('/')
def index():
# 本来想着将请求的ua和代理池再返回去,这样就能清晰的看到ua伪装和代理池效果
# 但是免费的代理池太难用了,请求结果只能看到ua伪装效果
url_root = request.url_root
ua = request.headers.get('User-Agent')
page = request.args.get('page')
return jsonify({"url_root": url_root, "UA": ua, "page": page})
if __name__ == "__main__":
app.run(debug=True)接下来就是爬虫文件了mw.py,代码简单,就是发十次请求,看ua伪装的结果。
import scrapy
class MwSpider(scrapy.Spider):
name = 'mw'
# allowed_domains = ['www.xxx.com']
start_urls = ['http://127.0.0.1:5000/?page=1']
url_tmp = 'http://127.0.0.1:5000/?page={}'
start_num = 2
end_num = 10
def parse(self, response):
print(response.json())
if self.start_num <= self.end_num:
yield scrapy.Request(url=self.url_tmp.format(self.start_num), callback=self.parse)
self.start_num += 1然后就是重要的下载中间件部分了middlewares.py:
import random
# 这里我用到了一个fake_useragent模块,用来产生随机的ua头的
# 详情参考:https://www.cnblogs.com/Neeo/articles/11525001.html
from fake_useragent import UserAgent
# 没有用到的中间件类和没用到的方法,我删掉了
class DmDownloaderMiddleware:
# 获取到的代理池,http和https分开存放
proxy_http = ["114.55.172.226:80","61.178.149.237:59042","43.132.251.60:8888","42.194.232.51:8088"]
proxy_https = ["166.111.185.77:7078", "1.189.209.123:1080"]
def process_request(self, request, spider):
# ua伪装
# UserAgent().random会随机产生一个ua字符串
request.headers["User-Agent"] = UserAgent().random
# # 由于免费代理池不好用,代码我注释了,知道如何配置就行了
# 代理池,也可以写在process_exception方法中
# if request.url.startswith("https"):
# proxy = "https://" + random.choice(self.proxy_https)
# else:
# proxy = "http://" + random.choice(self.proxy_http)
# request.meta['proxy'] = proxy
return None
def process_response(self, request, response, spider):
return response
def process_exception(self, request, exception, spider):
# 由于免费代理池不好用,代码我注释了,知道如何配置就行了
# if request.url.startswith("https"):
# proxy = "https://" + random.choice(self.proxy_https)
# else:
# proxy = "http://" + random.choice(self.proxy_http)
# request.meta['proxy'] = proxy
# return request # 必须将修改后request返回
pass接下来就是settings.py配置了:
BOT_NAME = 'dm'
SPIDER_MODULES = ['dm.spiders']
NEWSPIDER_MODULE = 'dm.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'dm (+http://www.yourdomain.com)'
LOG_LEVEL = "ERROR"
# Obey robots.txt rules
# ROBOTSTXT_OBEY = True
ROBOTSTXT_OBEY = False
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'dm.middlewares.DmDownloaderMiddleware': 543,
}来看运行效果:
D:\dm>scrapy crawl mw
{'UA': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36', 'page': '1', 'url_root': 'http://127.0.0.1:5000/'}
{'UA': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.67 Safari/537.36', 'page': '2', 'url_root': 'http://127.0.0.1:5000/'}
{'UA': 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36', 'page': '3', 'url_root': 'http://127.0.0.1:5000/'}
{'UA': 'Mozilla/5.0 (X11; OpenBSD i386) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.125 Safari/537.36', 'page': '4', 'url_root': 'http://127.0.0.1:5000/'}
{'UA': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1866.237 Safari/537.36', 'page': '5', 'url_root': 'http://127.0.0.1:5000/'}
{'UA': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2225.0 Safari/537.36', 'page': '6', 'url_root': 'http://127.0.0.1:5000/'}
{'UA': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2226.0 Safari/537.36', 'page': '7', 'url_root': 'http://127.0.0.1:5000/'}
{'UA': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.47 Safari/537.36', 'page': '8', 'url_root': 'http://127.0.0.1:5000/'}
{'UA': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1664.3 Safari/537.36', 'page': '9', 'url_root': 'http://127.0.0.1:5000/'}
{'UA': 'Mozilla/5.0 (X11; CrOS i686 4319.74.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.57 Safari/537.36', 'page': '10', 'url_root': 'http://127.0.0.1:5000/'}拦截响应:修改响应结果
这部分主要围绕解决动态数据处理展开的。
因为请求的结果中,不包含动态加载的数据,所以我们要对这个请求结果进行篡改,也就是从新想办法去拿到这个动态数据,拿到之后,替换到原来的请求对象,然后在后续解析环节就可以直接提取想要的数据了。
那么示例呢,就是爬取网易新闻页面的四大板块(国内,国际,军事、航空),截至到本示例的编写为止,这四大板块的新闻列表数据都是动态加载的,所以,是一个非常好的例子。
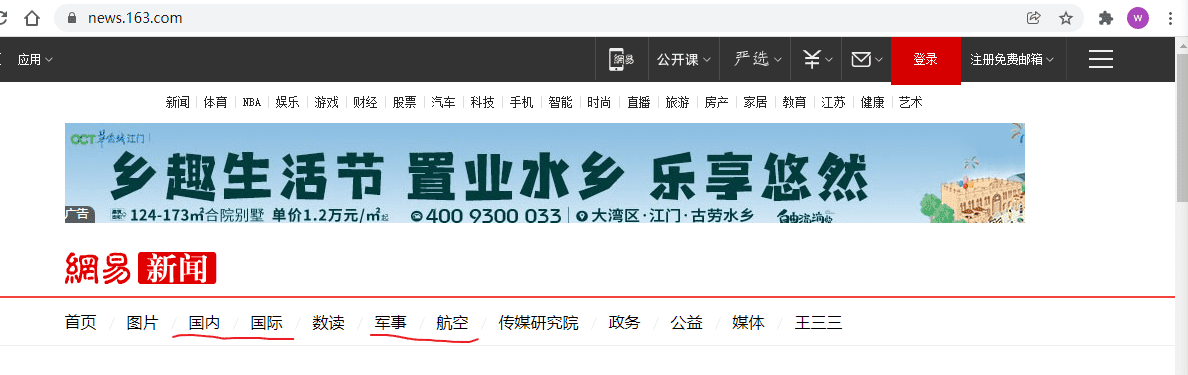
说说思路和需求吧:
需求:获取四大板块的新闻列表、从列表中拿到每条新闻的标题和详情页的链接,进一步获取详情页的新闻内容。
思路:
根据需求来说,爬虫类中最少需要编写三个解析方法:
self.parse解析新闻首页(不是动态的),从新闻首页中获取四大板块的页面链接。
self.parse_module解析每个板块的中的新闻列表。
难点在于新闻列表是动态加载的,所以解决办法就是拦截请求板块的url的响应对象(因为该对象中不包含动态加载的数据),拦截到之后,使用selenium重新向该url发请求,获取带动态加载出来的新闻列表的响应对象,然后返回给后续程序。对于不属于板块的url的响应对象,不做拦截。
当拿到动态的新闻列表数据,依次向每个新闻详情页(这个页面数据不是动态的)发送请求。
self.parse_details解析每个新闻详情页的数据。
scrapy startproject wangyi
cd wangyi
scrapy genspider news www.xxx.com上代码,首先是news.py:
import scrapy
from selenium import webdriver
from wangyi.items import WangyiItem
class NewsSpider(scrapy.Spider):
name = 'news'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://news.163.com/']
# 从新闻首页中解析出四个板块的url,放到下面的列表中
module_urls = []
def __init__(self):
""" 实例化一个浏览器对象,可以在后续篡改响应对象时反复使用 """
super(NewsSpider, self).__init__()
options = webdriver.ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable - logging'])
# 无头配置, 想看效果可以注释掉下面两行
options.add_argument('--headless')
options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(options=options)
# 隐士等待20秒 https://www.cnblogs.com/Neeo/articles/11005164.html
self.driver.implicitly_wait(time_to_wait=20)
def closed(self, spider):
""" 爬虫结束后,别忘了关闭浏览器对象 """
self.driver.quit()
def parse(self, response):
"""
解析新闻首页(非动态)中的四大板块链接,然后向其发送请求,得到每个板块的新闻列表(动态加载),需要篡改
"""
li_list = response.xpath('//*[@id="index2016_wrap"]/div[1]/div[2]/div[2]/div[2]/div[2]/div/ul/li')
# 从所有li中,挑选出四大板块所在的li
module_index = [2, 3, 5, 6]
# 将解析出来的板块链接添加到板块列表中,用于后续循环向其发送请求
for index in module_index:
module_url = li_list[index].xpath('./a/@href').extract_first()
module_name = li_list[index].xpath('./a/text()').extract_first()
# print(module_name, module_url)
"""
国内 https://news.163.com/domestic/
国际 https://news.163.com/world/
军事 https://war.163.com/
航空 https://news.163.com/air/
"""
self.module_urls.append(module_url)
# 依次对每个板块链接发送请求
for url in self.module_urls:
yield scrapy.Request(url=url, callback=self.parse_module)
def parse_module(self, response):
"""
解析新闻列表中的标题和对应的详情页的url
这个response已经是篡改后的response了,新闻列表数据都是完整的
然后依次向每个详情页发送请求,结果交给parse_details方法进行解析
"""
div_list = response.xpath('/html/body/div/div[3]/div[4]/div[1]/div[1]/div/ul/li/div/div')
module = response.xpath('/html/body/div/div[3]/div[2]/div[1]/h1/strong/text()').extract_first()
for div in div_list:
new_url = div.xpath('./div/div[1]/h3/a/@href | ./div/h3/a/@href').extract_first()
new_title = div.xpath('./div/div[1]/h3/a/text() | ./div/h3/a/text()').extract_first()
# 还是有些是None的,懒得再分析了, 就continue了,反正不影响后续操作
if new_url is None or new_title is None:
continue
# print(module, new_title, new_url)
item = WangyiItem()
item['new_module'] = module
item['new_title'] = new_title
yield scrapy.Request(url=new_url, callback=self.parse_details, meta={"item": item})
def parse_details(self, response):
""" 解析详情页结果 """
# 详情页就取新闻内容的第一段就行了,太长了,打印不好看
new_content = response.xpath('//*[@id="content"]/div[2]/p[1]/text()').extract()
new_content = ''.join(new_content)
new_content = new_content.strip().replace('\n', ' ')
item = response.meta['item']
item['new_content'] = new_content
yield item然后是下载中间件middlewares.py:
import time
from scrapy.http import HtmlResponse
from fake_useragent import UserAgent
from selenium.webdriver.common.by import By
class WangyiDownloaderMiddleware:
def process_request(self, request, spider):
# 经过测试,网易新闻轻易不会拦截爬虫,但是还是加上了ua伪装
# UserAgent().random会随机产生一个ua字符串
request.headers["User-Agent"] = UserAgent().random
def process_response(self, request, response, spider):
"""
该方法拦截所有的响应
request: 本次请求对象
response: 本次请求对象的请求结果,也就是响应对象
spider: 爬虫类的实例化对象,也就是当前示例中爬虫文件中,NewsSpider的实例化对象
要处理的问题:
经过页面分析,我们知道板块对应的url页面,新闻列表是动态加载的,所以response中不包含动态加载数据,
这需要我们手动处理,也就意味着要使用selenium重新向该板块url发请求,获取带新闻列表数据的响应对象,然后给到后续程序解析
但问题是,process_response方法会拦截所有的响应,所以要从所有的响应对象中过滤出来哪些应该拦截,哪些应该pass
"""
# 通过打印结果,可以发现,响应对象的url和请求的url是一样的,所以,我们可以任意使用其中之一进行筛选出要篡改的响应对象
# if response.url in spider.module_urls:
if request.url in spider.module_urls:
# print('板块对应的url', response.url, request.url)
"""
板块对应的url https://news.163.com/domestic/ https://news.163.com/domestic/
板块对应的url https://news.163.com/world/ https://news.163.com/world/
板块对应的url https://news.163.com/air/ https://news.163.com/air/
板块对应的url https://war.163.com/ https://war.163.com/
"""
# 这四个板块的响应对象要篡改
spider.driver.get(request.url) # 从新向动态数据所在的板块链接发送请求
time.sleep(3)
# 往下拖动进度条,再多加载一些新闻
body = spider.driver.find_element(By.TAG_NAME, 'body')
spider.driver.execute_script("arguments[0].scrollIntoView(false);", body)
time.sleep(3)
page_source = spider.driver.page_source # 包含了动态新闻的文本页面
# 原来的response不要了,重新封装一个包含动态数据的response
new_response = HtmlResponse(
url=request.url,
body=page_source,
encoding='utf-8',
request=request
)
# 将篡改后的response返回给后续的程序进行解析
return new_response
else: # 其他响应对象不做处理,直接放行
return response
def process_exception(self, request, exception, spider):
pass紧接着是items.py:
import scrapy
class WangyiItem(scrapy.Item):
# define the fields for your item here like:
new_module = scrapy.Field()
new_title = scrapy.Field()
new_content = scrapy.Field()还有pipelines.py:
class WangyiPipeline:
def process_item(self, item, spider):
print(item) # 持久化就省略了,打印意思下得了
return item最后别忘了settings.py:
BOT_NAME = 'wangyi'
SPIDER_MODULES = ['wangyi.spiders']
NEWSPIDER_MODULE = 'wangyi.spiders'
LOG_LEVEL = "ERROR"
# Obey robots.txt rules
# ROBOTSTXT_OBEY = True
ROBOTSTXT_OBEY = False
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'wangyi.middlewares.WangyiDownloaderMiddleware': 543,
}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'wangyi.pipelines.WangyiPipeline': 300,
}CrawlSpider
常见报错
AttributeError: 'TelnetConsole' object has no attribute 'port'
在settings.py中设置:
TELNETCONSOLE_PORT = None-port
在settings.py中设置:
TELNETCONSOLE_PORT = None