 王张开
王张开一些概念
所有的示例都基于Python3.12解释器运行的,如果没有特别强调,默认都是win11系统下完成的。
进程和线程可以在生活中找到很多类似的场景和概念:
- 一个工厂,至少有一个车间,一个车间中至少有一个工人,最终是工人在工作。
- 一个程序,至少有一个进程,一个进程中至少有一个线程,最终是线程在工作。
而在Python中,每当你在使用python xxx.py运行时,内部就创建一个进程(主进程),在进程中创建了一个线程(主线程),由线程逐行运行xxx.py中的代码,哪怕xxx.py中一行代码也没有;哪怕运行时间极其短暂,但该给的资源、该启的进程和线程一个都不能少。
print("hello world")进程和线程:
- 进程,是操作系统(计算机)来进行资源分配的最小单元,也是操作系统通过这个进程来感知某个软件是否在运行或者停止的重要方式,启动进程就要给其分配资源,进程停止,就要收回分配的资源。在进程运行期间为真正干活的线程提供各种资源。
- 线程,是计算机中可以被cpu调度的最小单元,一个进程中可以有多个线程,同一个进程中的线程可以共享此进程中的资源。线程也是真正来干活的。
以前我们开发的程序中所有的行为都只能通过串行的形式运行,排队逐一执行,前面未完成,后面也无法继续。例如:
import time
import requests
url_list = [
('http://httpbin.org/post', {'k1': 'v1'}),
('http://httpbin.org/post', {'k2': 'v2'}),
('http://httpbin.org/post', {'k3': 'v3'}),
]
def send_request(url, data):
response = requests.post(url, data=data)
print(response.json())
if __name__ == '__main__':
start = time.time()
for url, data in url_list:
send_request(url, data)
end = time.time()
print('Time taken:', end - start) # Time taken: 1.5109755992889404后续通过 进程 和 线程 都可以将 串行 的程序变为并发,对于上述示例来说就是同时下载三个视频,这样很短的时间内就可以下载完成。
多线程
基于多线程对上述串行示例进行优化:
- 一个工厂,创建一个车间,这个车间中创建 3个工人,并行处理任务。
- 一个程序,创建一个进程,这个进程中创建 3个线程,并行处理任务。
import time
import requests
url_list = [
('http://httpbin.org/post', {'k1': 'v1'}),
('http://httpbin.org/post', {'k2': 'v2'}),
('http://httpbin.org/post', {'k3': 'v3'}),
]
def send_request(url, data):
response = requests.post(url, data=data)
print(response.json())
if __name__ == '__main__':
start = time.time()
for url, data in url_list:
send_request(url, data)
end = time.time()
print('Time taken:', end - start) # Time taken: 1.5109755992889404import time
import threading
import requests
url_list = [
('http://httpbin.org/post', {'k1': 'v1'}),
('http://httpbin.org/post', {'k2': 'v2'}),
('http://httpbin.org/post', {'k3': 'v3'}),
]
def send_request(url, data):
response = requests.post(url, data=data)
print(response.json())
if __name__ == '__main__':
start = time.time()
# for url, data in url_list:
# send_request(url, data)
t_list = []
for url, data in url_list:
# 创建线程,让每个线程都去执行send_request函数,args用来携带参数
# 注意,args是以元组形式传参,如果传一个值,别忘了逗号,即args=(url,)
t = threading.Thread(target=send_request, args=(url, data))
t.start()
t_list.append(t)
# 为了能统计出来时间,这里先这么写,后面会解释为啥这么写
for t in t_list:
t.join()
end = time.time()
print('Time taken:', end - start) # Time taken: 0.5147087574005127多进程
基于多进程对之前串行示例进行优化:
- 一个工厂,创建 三个车间,每个车间 一个工人(共3人),并行处理任务。
- 一个程序,创建 三个进程,每个进程 一个线程(共3人),并行处理任务。
import time
import requests
url_list = [
('http://httpbin.org/post', {'k1': 'v1'}),
('http://httpbin.org/post', {'k2': 'v2'}),
('http://httpbin.org/post', {'k3': 'v3'}),
]
def send_request(url, data):
response = requests.post(url, data=data)
print(response.json())
if __name__ == '__main__':
start = time.time()
for url, data in url_list:
send_request(url, data)
end = time.time()
print('Time taken:', end - start) # Time taken: 1.5109755992889404import time
import threading
from multiprocessing import Process
import requests
url_list = [
('http://httpbin.org/post', {'k1': 'v1'}),
('http://httpbin.org/post', {'k2': 'v2'}),
('http://httpbin.org/post', {'k3': 'v3'}),
]
def send_request(url, data):
response = requests.post(url, data=data)
print(response.json())
if __name__ == '__main__':
start = time.time()
# for url, data in url_list:
# send_request(url, data)
p_list = []
for url, data in url_list:
# 创建线程,让每个线程都去执行send_request函数,args用来携带参数
# 注意,args是以元组形式传参,如果传一个值,别忘了逗号,即args=(url,)
p = Process(target=send_request, args=(url, data))
p.start()
p_list.append(p)
for p in p_list:
p.join()
end = time.time()
print('Time taken:', end - start) # Time taken: 0.995246171951294综上所述,大家会发现 多进程 的开销比 多线程 的开销大。哪是不是使用多线程要比多进程更好呀?
接下来,给大家再来介绍一个Python内置的GIL锁的知识,然后再根据进程和线程各自的特点总结各自适合应用场景。
GIL锁
GIL, 全局解释器锁(Global Interpreter Lock),是CPython解释器特有一个玩意,让一个进程中同一个时刻只能有一个线程可以被CPU调用,如下图左侧所示。
如果程序想利用计算机的多核优势,让CPU同时处理多个任务,适合用多进程开发(即使资源开销大),如下图中间所示。
如果程序不利用计算机的多核优势,适合用多线程开发,如下图右侧所示。
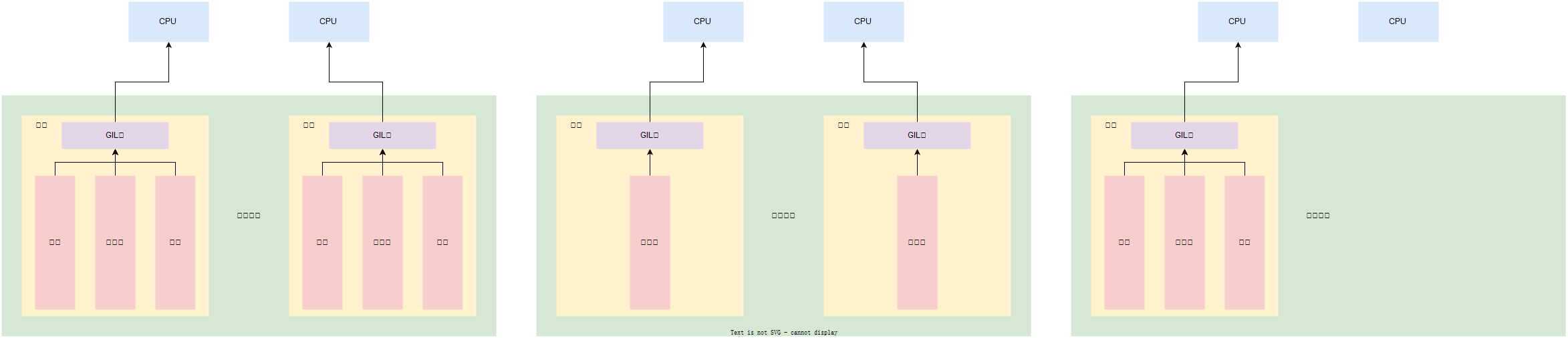
常见的程序开发中,计算操作需要使用CPU多核优势,IO操作不需要利用CPU的多核优势,所以,就有这一句话:
- 计算密集型,用多进程,例如:大量的数据计算【累加计算示例】。
- IO密集型,用多线程,例如:文件读写、网络数据传输【网络请求
httpbin示例】。
import time
start = time.time()
result = 0
for i in range(100000000):
result += i
print(result)
end = time.time()
print("耗时:", end - start) # 耗时: 5.252034425735474import time
import multiprocessing
def task(start, end, queue):
result = 0
for i in range(start, end):
result += i
queue.put(result)
if __name__ == '__main__':
queue = multiprocessing.Queue()
start_time = time.time()
p1 = multiprocessing.Process(target=task, args=(0, 50000000, queue))
p1.start()
p2 = multiprocessing.Process(target=task, args=(50000000, 100000000, queue))
p2.start()
v1 = queue.get(block=True) #阻塞
v2 = queue.get(block=True) #阻塞
print(v1 + v2)
end_time = time.time()
print("耗时:", end_time - start_time) # 耗时: 1.4613192081451416import time
import threading
from multiprocessing import Process
import requests
url_list = [
('http://httpbin.org/post', {'k1': 'v1'}),
('http://httpbin.org/post', {'k2': 'v2'}),
('http://httpbin.org/post', {'k3': 'v3'}),
]
def send_request(url, data):
response = requests.post(url, data=data)
print(response.json())
if __name__ == '__main__':
start = time.time()
# for url, data in url_list:
# send_request(url, data)
p_list = []
for url, data in url_list:
# 创建线程,让每个线程都去执行send_request函数,args用来携带参数
# 注意,args是以元组形式传参,如果传一个值,别忘了逗号,即args=(url,)
p = Process(target=send_request, args=(url, data))
p.start()
p_list.append(p)
for p in p_list:
p.join()
end = time.time()
print('Time taken:', end - start) # Time taken: 0.995246171951294多进程中嵌套多线程
当然,在程序开发中多线程和多进程是可以结合使用,例如:创建2个进程(建议与CPU个数相同),每个进程中创建3个线程。
import multiprocessing
import threading
def thread_task():
pass
def task():
t1 = threading.Thread(target=thread_task)
t1.start()
t2 = threading.Thread(target=thread_task)
t2.start()
t3 = threading.Thread(target=thread_task)
t3.start()
if __name__ == '__main__':
p1 = multiprocessing.Process(target=task, args=())
p1.start()
p2 = multiprocessing.Process(target=task, args=())
p2.start()当然这么用